SVM: plot decision surface when working with more than 2 features
我正在使用 scikit-learn 的乳腺癌数据集,该数据集包含 30 个特征。
遵循本教程对于不那么令人沮丧的虹膜数据集,我想出了如何绘制区分”良性”和”恶性”类别的决策表面,当考虑数据集的前两个特征(平均半径和平均纹理).
这是我得到的:
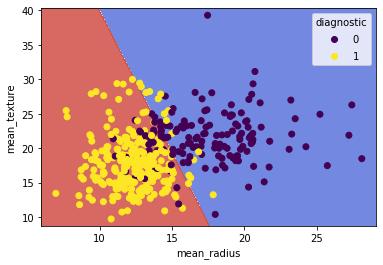
但是当使用数据集中的所有特征时,如何表示计算出的超平面呢?
我知道我无法绘制 30 维的图形,但我想将运行 svm.SVC(kernel=’linear’, C=1).fit(X_train, y_train) 时创建的超平面” 投影”到=”” 2d=”” 散点图上,显示平均纹理与平均半径的关系。<=”” p=”” class=”box-hide box-show”>
我读到了关于使用 PCA 来降低维度的信息,但我怀疑拟合”降维”数据集与将计算出的所有 30 个特征的超平面投影到 2D 图上是不同的。
到目前为止,这是我的代码:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from sklearn import datasets
import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn import svm import numpy as np #Load dataset # Split dataset into training set and test set h = .02 # mesh step
x_min, x_max = X_train[:, 0].min() – 1, X_train[:, 0].max() + 1
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) |
- 我提供了2个例子。一个 2D 使用 3 个特征,一个 3D 使用 3 个特征。希望这可以帮助
您无法将许多特征的决策面可视化。这是因为维度太多,无法可视化 N 维表面。
我在这里也写了一篇关于这个的文章:
https://towardsdatascience.com/support-vector-machines-svm-clearly-explained-a-python-tutorial-for-classification-problems-29c539f3ad8?source=friends_link
- 嘿,谢谢你的回答,塞拉卢克。我真的很喜欢 3 个功能的 3D 情节;我相信这在将来会派上用场!
你不能在没有任何二维变换的情况下绘制 30 维数据。
https://github.com/tmadl/highdimensional-decision-boundary-plot
什么是 Voronoi Tesselation?
给定一组 P := {p1, …, pn} 的站点,Voronoi Tessellation 是将空间细分为 n 个单元,P 中的每个站点一个单元,其属性是点 q 位于对应的单元中到一个站点 pi 当 i 不同于 j 时 d(pi, q) < d(pj, q)。 Voronoi Tessellation 中的段对应于平面中与两个最近站点等距的所有点。 Voronoi Tessellations 在计算机科学中有应用。 – https://philogb.github.io/blog/2010/02/12/voronoi-tessellation/
在几何学中,质心 Voronoi 细分 (CVT) 是一种特殊类型的 Voronoi 细分或 Voronoi 图。当每个 Voronoi 单元的生成点也是其质心(即算术平均值或质心)时,Voronoi Tesselation被称为质心。它可以看作是对应于生成器的最佳分布的最佳分区。许多算法可用于生成质心 Voronoi 细分,包括用于 K-means 聚类的 Lloyd 算法或 BFGS 等准牛顿方法。 – 维基
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import numpy as np, matplotlib.pyplot as plt
from sklearn.neighbors.classification import KNeighborsClassifier from sklearn.datasets.base import load_breast_cancer from sklearn.manifold.t_sne import TSNE from sklearn import svm
bcd = load_breast_cancer() h = .02 # mesh step clf = svm.SVC(kernel=‘linear’, C=C) # Linear Kernel
resolution = 100 # 100×100 background pixels # approximate Voronoi tesselation on resolution x resolution grid using 1-NN #plot |

- 谢谢你的回答,弗西弗!我需要绕开这个问题……我的理解是,你图中表示的决策面是基于所有 30 个特征建立的;我对么?仍然让我感到困惑的部分是 KNeighborsClassifier(n_neighbors=1).fit(X_Train_embedded, y_predicted) 因为它使用仅针对 2 个特征计算的 X_Train_embedded 和基于所有 30 个特征的 y_predicted ……
来源:https://www.codenong.com/61225052/



