新入手,小白的我,在我眼里 Request 爬虫永远只有四大步,不服来辩?
- 确定 URL,构造请求头
- 发送请求,获取响应
- 解析响应,获取数据
- 保存数据
目标:根据视频 BV,获取 B 站视频弹幕
代码地址如下: 抓包确定 URL:
导入:
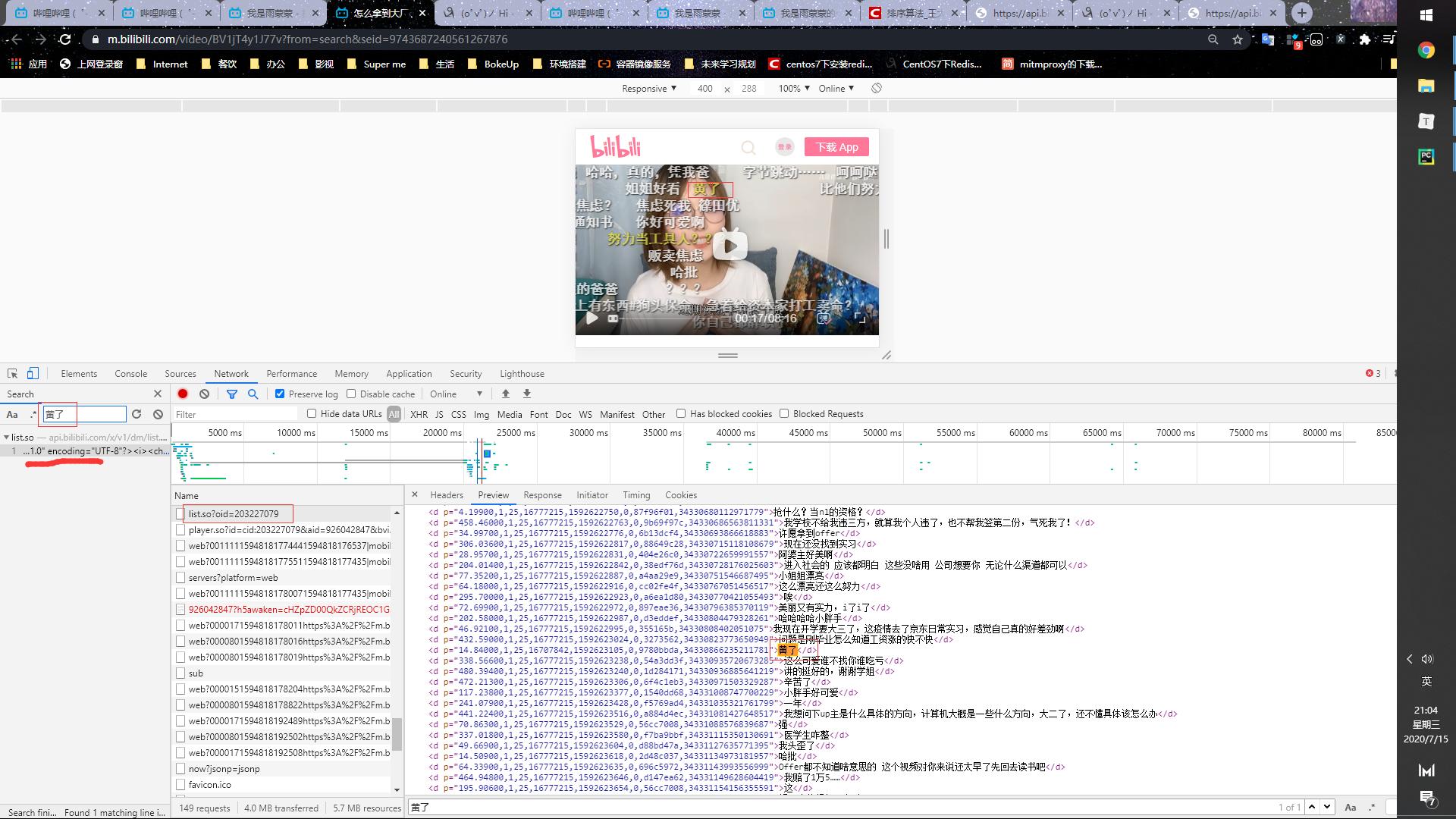
视频都有一个唯一区分视频:BV 号 那么视频的 URL 规则为:’https://wwww.bilibili.com/video/BV{BVID}’ 找一下弹幕的地址,直接 search,即可!如下
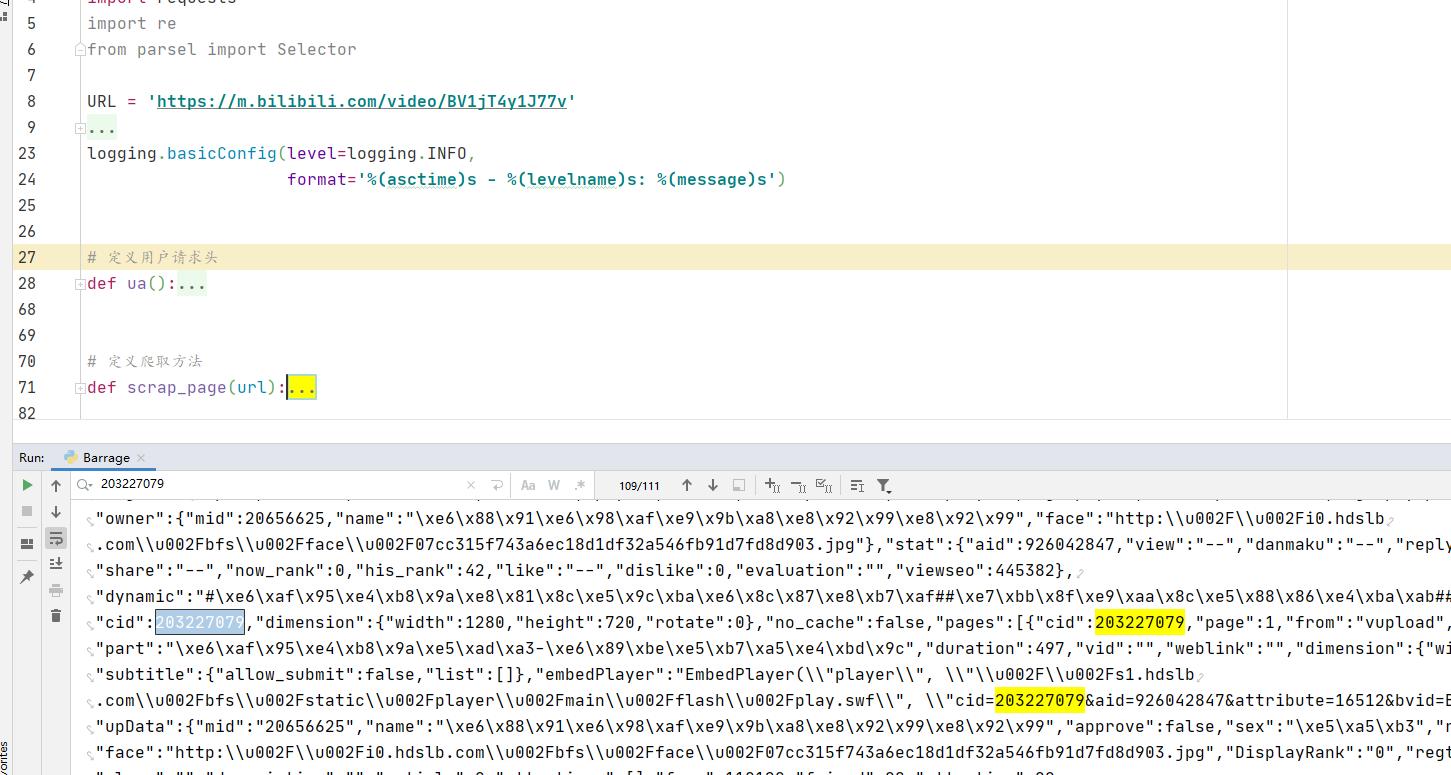
由以上抓包可知,弹幕的 URL:’https://api.bilibili.com/x/v1/dm/list.so?oid=oid‘, 我们获取到 oid 那么这一步就完成了 来,回头去找一下 oid 从何而来呢? 据老夫多年经验指引,他一定在视频 URL 里面。(其实当时也找了挺久的,甚至逆向那一手,断点调试、调用堆栈等等什么都用出来了。最终还是功夫不负有心人,找到了) 其实回头看,oid 是等于 video_URL 页面里面的 cid 参数的(验证了 Payne 式猜想)。过程是难受的
URL,其参数规则也找到了,那么还不就随我为所欲为了。只要拿到视频地址,那不就可以直接拿到弹幕了么。of course!
此处省略 3 万字(请求,解析,网络原理。。。)
其实当时知道两个方法都去试了,JS 那个就不说了,有兴趣的盆友,可以去搞一下 说说这个提取 cid 参数吧,我用的是正则,这种情况最好是用正则,不过也看个人喜好吧。 可以回头看第二张图,初一乍看我好像不会,啊哈哈~
经过优化后(主要是看了其他视频的那啥之后):写出这个神奇的正则
谢谢你认真看到了末尾,那我也写点私活吧。欢迎查阅源码与 star
1 |
其实关于很多网站(普通)的参数就算是有JS加密,以及混淆。并不代表就一定需要去解密,去逆向。有时候真的只需要serch一下惊喜多多,望诸君切记、切记。 |
来源:https://cuiqingcai.com/9501.html



