我们知道,Seq2Seq 现在已经成为了机器翻译、对话聊天、文本摘要等工作的重要模型,真正提出 Seq2Seq 的文章是《Sequence to Sequence Learning with Neural Networks》,但本篇《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》比前者更早使用了 Seq2Seq 模型来解决机器翻译的问题,本文是该篇论文的概述。
发布信息
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation 2014 年 6 月发布于 Arxiv 上,一作是 Kyunghyun Cho,当时来自蒙特利尔大学,现在在纽约大学任教。
摘要
这篇论文中提出了一种新的模型,叫做 RNN Encoder-Decoder, 并将它用来进行机器翻译和比较不同语言的短语 / 词组之间的语义近似程度。这个模型由两个 RNN 组成,其中 Encoder 用来将输入的序列表示成一个固定长度的向量,Decoder 则使用这个向量重建出目标序列,另外该论文提出了 GRU 的基本结构,为后来的研究奠定了基础。 因此本文的主要贡献是:
- 提出了一种类似于 LSTM 的 GRU 结构,并且具有比 LSTM 更少的参数,更不容易过拟合。
- 较早地将 Seq2Seq 应用在了机器翻译领域,并且取得了不错的效果。
模型
本文提出的模型结构如下图所示: 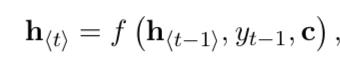
这里首先对输入上文 x 走一遍 RNN,然后得到一个固定长度的向量 c,作为 Encoder,然后接下来再根据 c 和后续隐状态和输入状态来得到后续状态,Encoder 的行为比较简单,重点在 Decoder 上。
Decoder 中 t 时刻的内部状态的 ht 为:
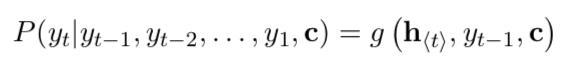
该时刻的输出概率则为: 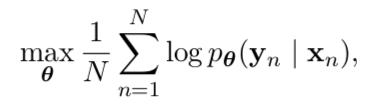 模型训练时则去最大化给定输入序列 x 时输出序列为 y 的条件概率:
模型训练时则去最大化给定输入序列 x 时输出序列为 y 的条件概率:  以上便是核心的公式,上面的这个就是该模型的优化目标。 在机器翻译上,作者用 Moses (一个 SMT 系统) 建立了一个 phrase based 的翻译模型作为 baseline system ,然后对比了以下四个模型的 BLEU 值
以上便是核心的公式,上面的这个就是该模型的优化目标。 在机器翻译上,作者用 Moses (一个 SMT 系统) 建立了一个 phrase based 的翻译模型作为 baseline system ,然后对比了以下四个模型的 BLEU 值
- Baseline configuration
- Baseline + RNN
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty
四种不同的模型的 BLEU 值如下表所示:
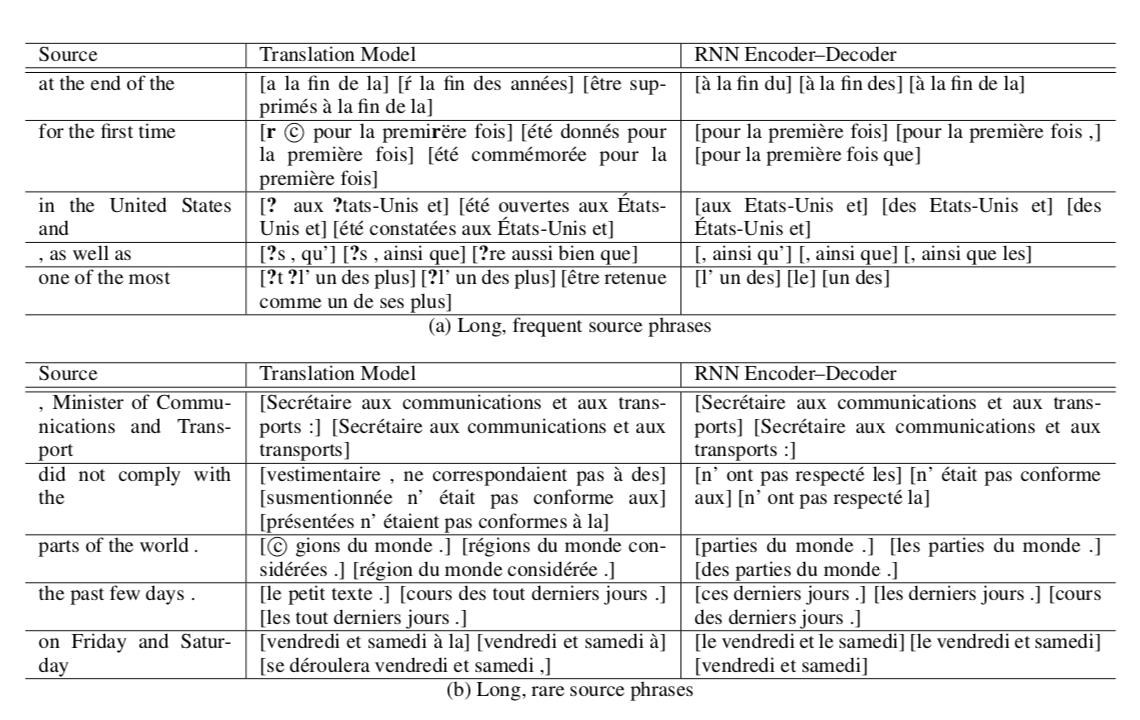
phrase pair 打分的结果如下: 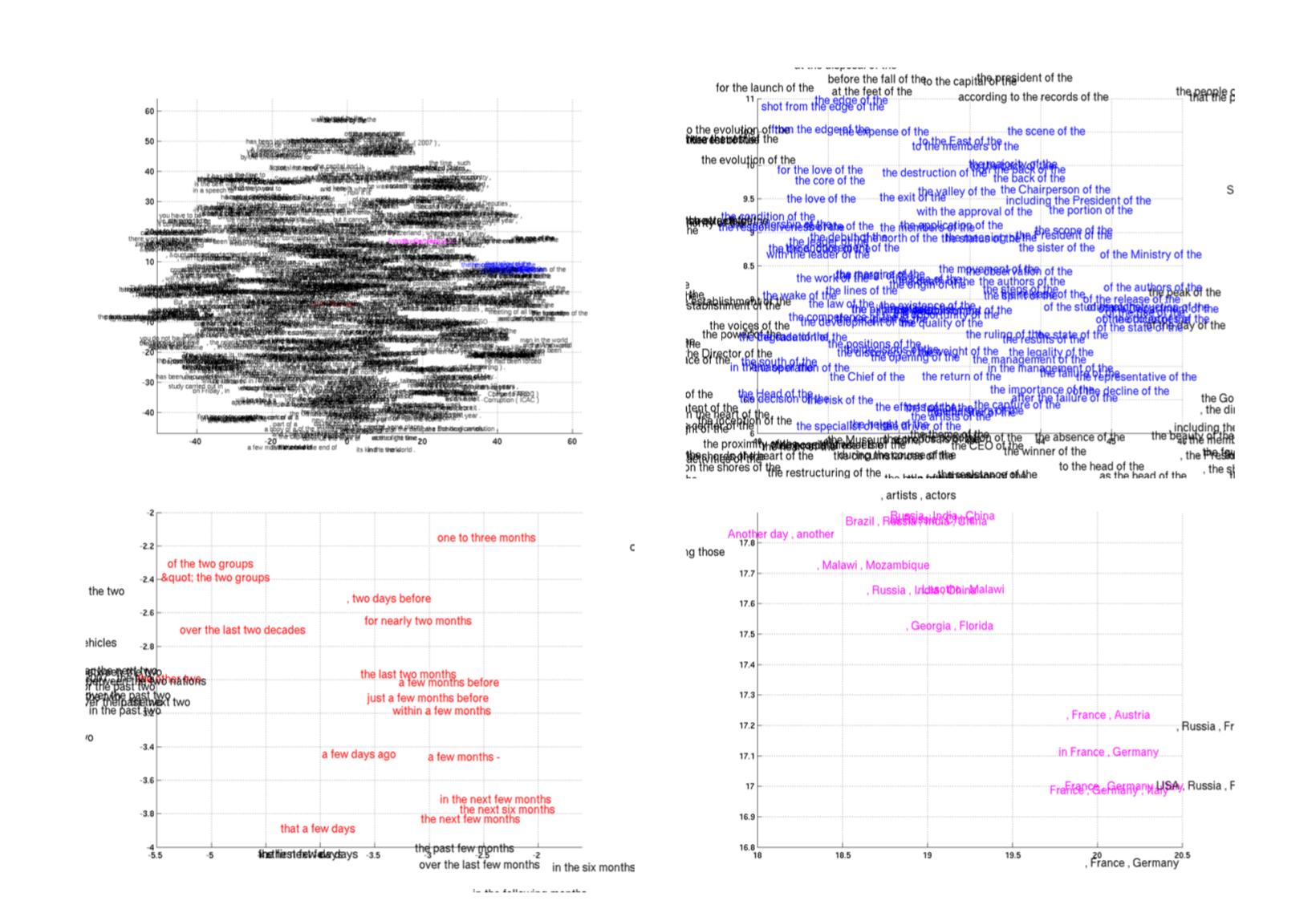 其中第一栏是输入的英语 phrase ,第二栏是用传统的模型得到的最近似的三个法语 phrase,第三栏是用 Encoder-Decoder 模型得到的最近似的三个 phrase。 另外作者还说明该模型可以学习到一个比较好的效果的 Word Embedding 结果,附图如下:
其中第一栏是输入的英语 phrase ,第二栏是用传统的模型得到的最近似的三个法语 phrase,第三栏是用 Encoder-Decoder 模型得到的最近似的三个 phrase。 另外作者还说明该模型可以学习到一个比较好的效果的 Word Embedding 结果,附图如下:  左上角的图代表全局的 Embedding 结果,另外三个图是局部结果,可以看到类似的名词都被聚到了一起。
左上角的图代表全局的 Embedding 结果,另外三个图是局部结果,可以看到类似的名词都被聚到了一起。
GRU
另外本文的一个主要贡献是提出了 GRU 的门结构,相比 LSTM 更加简洁,而且效果不输 LSTM,关于它的详细公式推导,可以直接参考论文的最后的附录部分,有详细的介绍,在此截图如下: 


结语
本篇论文算是为 Seq2Seq 的研究开了先河,而且其提出的 GRU 结构也为后来的研究做好了铺垫,得到了广泛应用,非常值得一读。
参考
来源:https://cuiqingcai.com/5737.html



