前几天,大才发了一个自己写的框架,介绍地址在这里, GIT 地址在这里。
今天在阿里云上试用了一下,在这里做一个简单的说明。
1、配置环境
阿里云的版本是 2.7.5,所以用 pyenv 新安装了一个 3.6.4 的环境,安装后使用 pyenv global 3.6.4 即可使用 3.6.4 的环境,我个人比较喜欢这样,切换自如,互不影响。 如下图:  接下来按照大才的文章,pip install gerapy 即可,这一步没有遇到什么问题。有问题的同学可以向大才提 issue。
接下来按照大才的文章,pip install gerapy 即可,这一步没有遇到什么问题。有问题的同学可以向大才提 issue。
2. 开启服务
首先去阿里云的后台设置安全组 ,我的是这样: 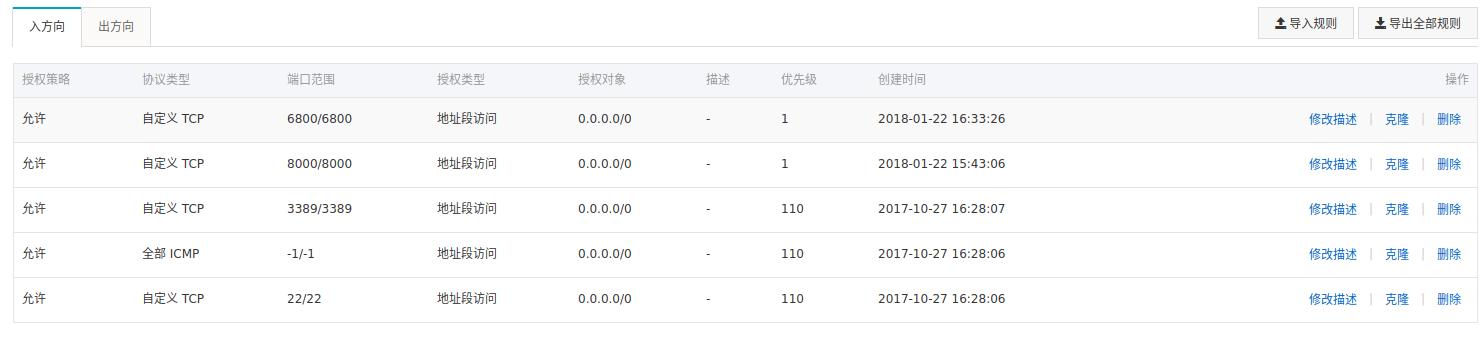 然后到命令窗口对 8000 和 6800 端口放行即可。 接着执行
然后到命令窗口对 8000 和 6800 端口放行即可。 接着执行
gerapy init cd gerapy gerapy migrate ** # 注意下一步 ** **gerapy runserver 0.0.0.0:8000 【如果你是在本地,执行 gerapy runserver即可,如果你是在阿里云上,你就要改成前面这样来执行】**
现在在浏览器里访问:ip:8000 应该就可以看到主界面了  里面的各个的含义见大才的文章。
里面的各个的含义见大才的文章。
3. 创建项目
在 gerapy 下的 projects 里面新建一个 scrapy 爬虫,在这里我搞的是最简单的:
scrapy startproject gerapy_test cd gerapy_test scrapy genspider baidu www.baidu.com
这样就是一个最简单的爬虫了,修改一个 settings.py 中的 ROBOTSTXT_OBEY=False, 然后修改一个 spiders 下面的 baidu.py, 这里随意,我这里设置的是输出返回的 response.url
4. 安装 scrapyd
pip install scrapyd
安装好以后,命令行执行
scrapyd
然后浏览器中打开 ip:6800,如果你没有修改配置,应该这里会打不开,clients 那里配置的时候,也应该会显示为 error,就像这样: 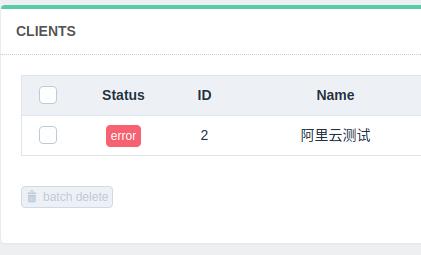 后来找了一下原因发现 scrapyd 默认打开的也是 127.0.0.1
后来找了一下原因发现 scrapyd 默认打开的也是 127.0.0.1  所以这个时候就要改一下配置,具体可以参考这里, 我是这么修改:
所以这个时候就要改一下配置,具体可以参考这里, 我是这么修改:
vim ~/.scrapyd.conf [scrapyd] bind_address = 0.0.0.0
在刷新一下,就会看到前面 error 变成了 normal 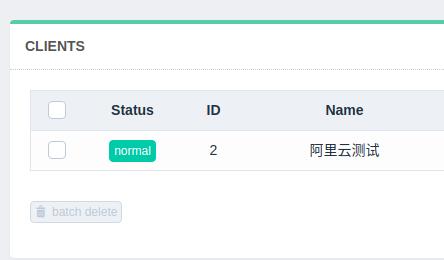
5. 打包,部署,调度
这几步大才的文章里都有详细说明,打包完,部署,在进入 clients 的调度界面,点击 run 按钮即可跑爬虫了 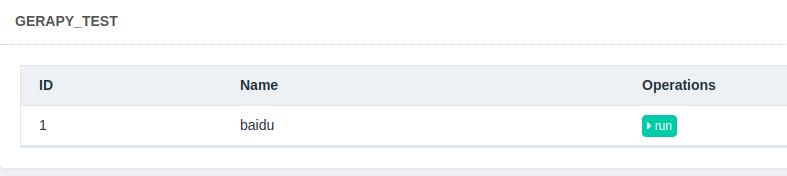

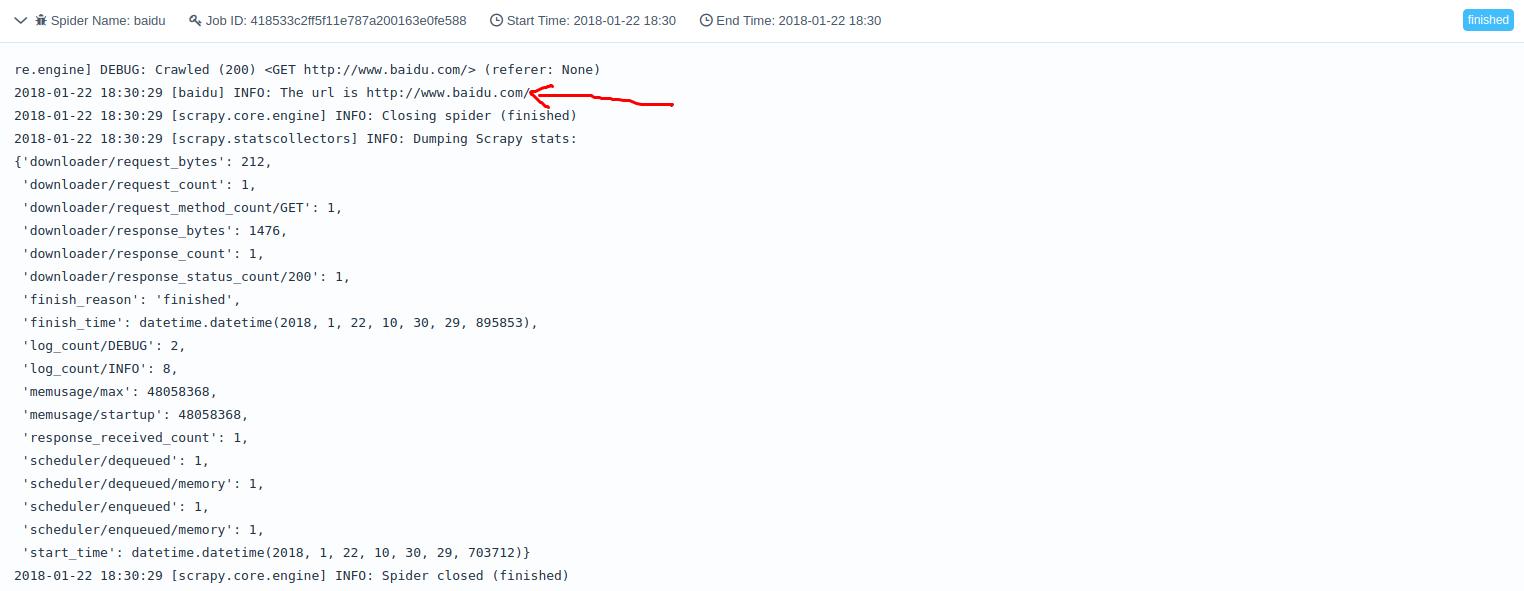 可以看到输出的结果了。
可以看到输出的结果了。
6. 结语
建议大家可以试着用一下,很方便,我这里只是很简单的使用了一下。
来源:https://cuiqingcai.com/5006.html



