大家好,我是四毛,下面是我的个人公众号,欢迎关注。有问题的可以私信我,看到就会回复。
更新 2018 年 08 月 03 日 14:39:32
其实可以利用 scrapy 的扩展展示更多的数据,立个 flag,后面更新上来
好,开始今天的文章。 今天主要是来说一下怎么可视化来监控你的爬虫的状态。 相信大家在跑爬虫的过程中,也会好奇自己养的爬虫一分钟可以爬多少页面,多大的数据量,当然查询的方式多种多样。今天我来讲一种可视化的方法。
关于爬虫数据在 mongodb 里的版本我写了一个可以热更新配置的版本,即添加了新的爬虫配置以后,不用重启程序,即可获取刚刚添加的爬虫的状态数据,大家可以通过关注我的公众号以后, 回复 “可视化” 即可获取脚本地址。
1. 成品图
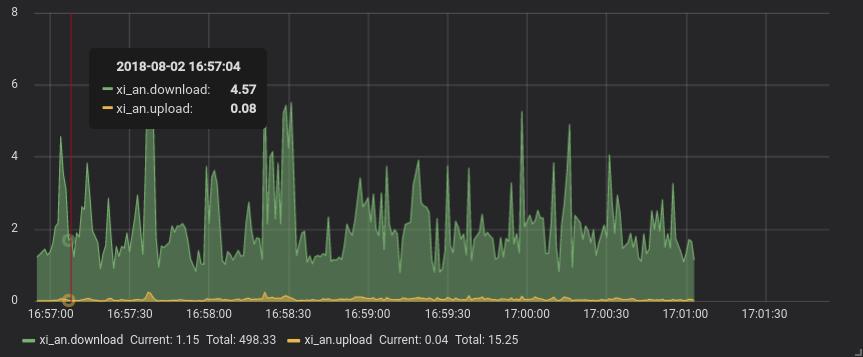
 这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为 M。爬虫的原理都是一样的,只不过将数据存到 InfluxDB 的方式不一样而已, 如下图。
这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为 M。爬虫的原理都是一样的,只不过将数据存到 InfluxDB 的方式不一样而已, 如下图。
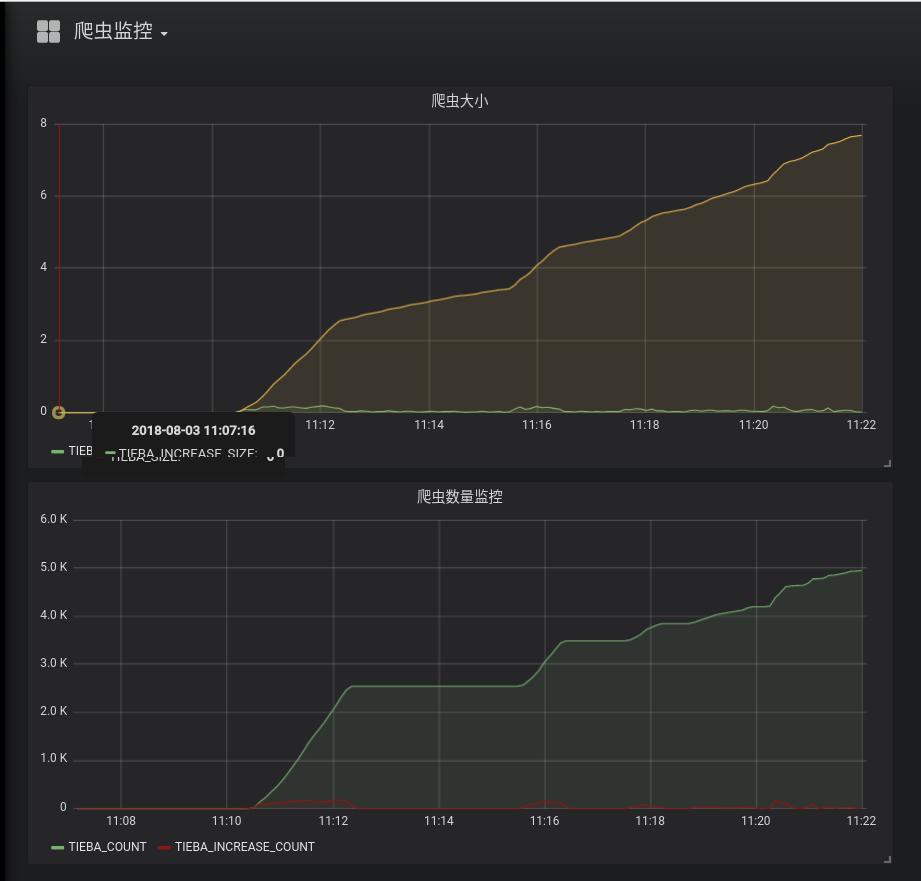
可以实现对爬虫数量,增量,大小,大小增量的实时监控。
2. 环境
- InfluxDb,是目前比较流行的时间序列数据库;
- Grafana,一个可视化面板(Dashboard),有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus 和 OpenTSDB 作为数据源
- Ubuntu
-
influxdb(pip install influxdb)
-
Python 2.7
3. 原理
获取要展示的数据,包含当前的时间数据,存到 InfluxDb 里面,然后再到 Grafana 里面进行相应的配置即可展示;
4. 安装
4.1 Grafana 安装
官方安装指导 安装好以后,打开本地的 3000 端口,即可进入管理界面,用户名与密码都是 admin。
4.2 InfulxDb 安装
这个安装就网上自己找吧,有很多的配置我都没有配置,就不在这里误人子弟了。
5. InfluxDb 简单操作
碰到了数据库,肯定要把增删改查学会了啊, 和 sql 几乎一样,只有一丝丝的区别,具体操作,大家可以参考官方的文档。
- influx 进入命令行
- CREATE DATABASE test 创建数据库
- show databases 查看数据库
- use test 使用数据库
- show series 看表
- select * from table_test 选择数据
- DROP MEASUREMENT table_test 删表
6. 存数据
InfluxDb 数据库的数据有一定的格式,因为我都是利用 python 库进行相关操作,所以下面将在 python 中的格式展示一下:
1 |
json_body = [ |
其中:
- measurement, 表名
- time,时间
- tags,标签
- fields,字段
可以看到,就是个列表里面,嵌套了一个字典。其中,对于时间字段,有特殊要求,可以参考这里, 下面是 python 实现方法:
1 |
from datetime import datetime |
所以,到这里,如何将爬虫的相关属性存进去呢?以 MongoDB 为例
1 |
mongodb_client = pymongo.MongoClient(uri) |
完整代码,关注上面的公众号,发送 “” 可视化 “” 即可获取。 那么现在我们已经往数据里存了数据了,那么接下来要做的就是把存的数据展示出来。
7. 展示数据
7.1 配置数据源
以 admin 登录到 Grafana 的后台后,我们首先需要配置一下数据源。点击左边栏的最下面的按钮,然后点击 DATA SOURCES,这样就可以进入下面的页面: 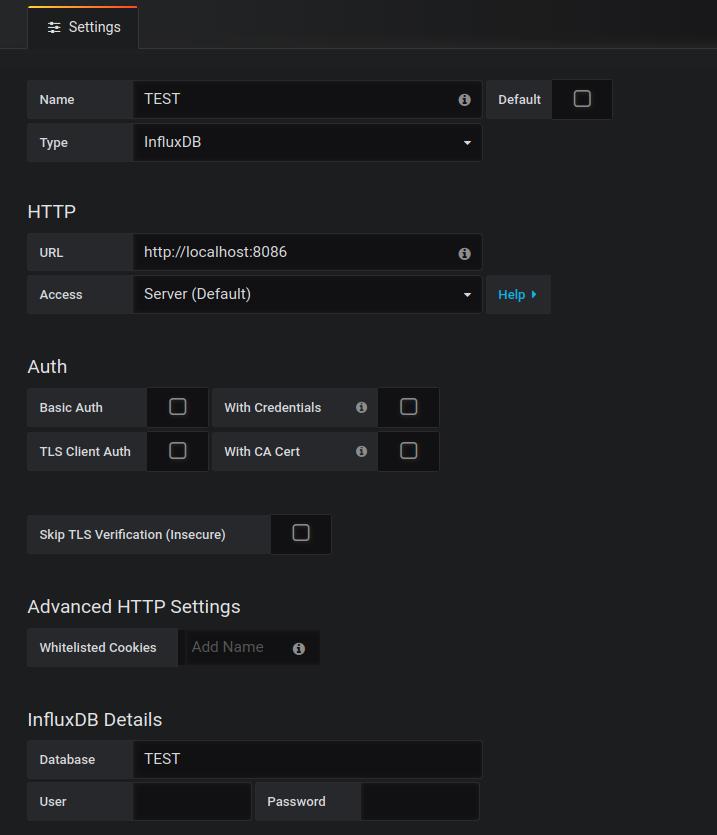 点击 ADD DATA SOURCE,进行配置即可,如下图:
点击 ADD DATA SOURCE,进行配置即可,如下图:  其中,name 自行设定;Type 选择 InfluxDB;url 为默认的 http://localhost:8086, 其他的因为我前面没有进行配置,所以默认的即可。然后在 InfluxDB Details 里的填入 Database 名,最后点击测试,如果没有报错的话,则可以进入下一步的展示数据了;
其中,name 自行设定;Type 选择 InfluxDB;url 为默认的 http://localhost:8086, 其他的因为我前面没有进行配置,所以默认的即可。然后在 InfluxDB Details 里的填入 Database 名,最后点击测试,如果没有报错的话,则可以进入下一步的展示数据了;
7.2 展示数据
点击左边栏的 + 号,然后点击 GRAPH  接着点击下图中的 edit 进入编辑页面:
接着点击下图中的 edit 进入编辑页面: 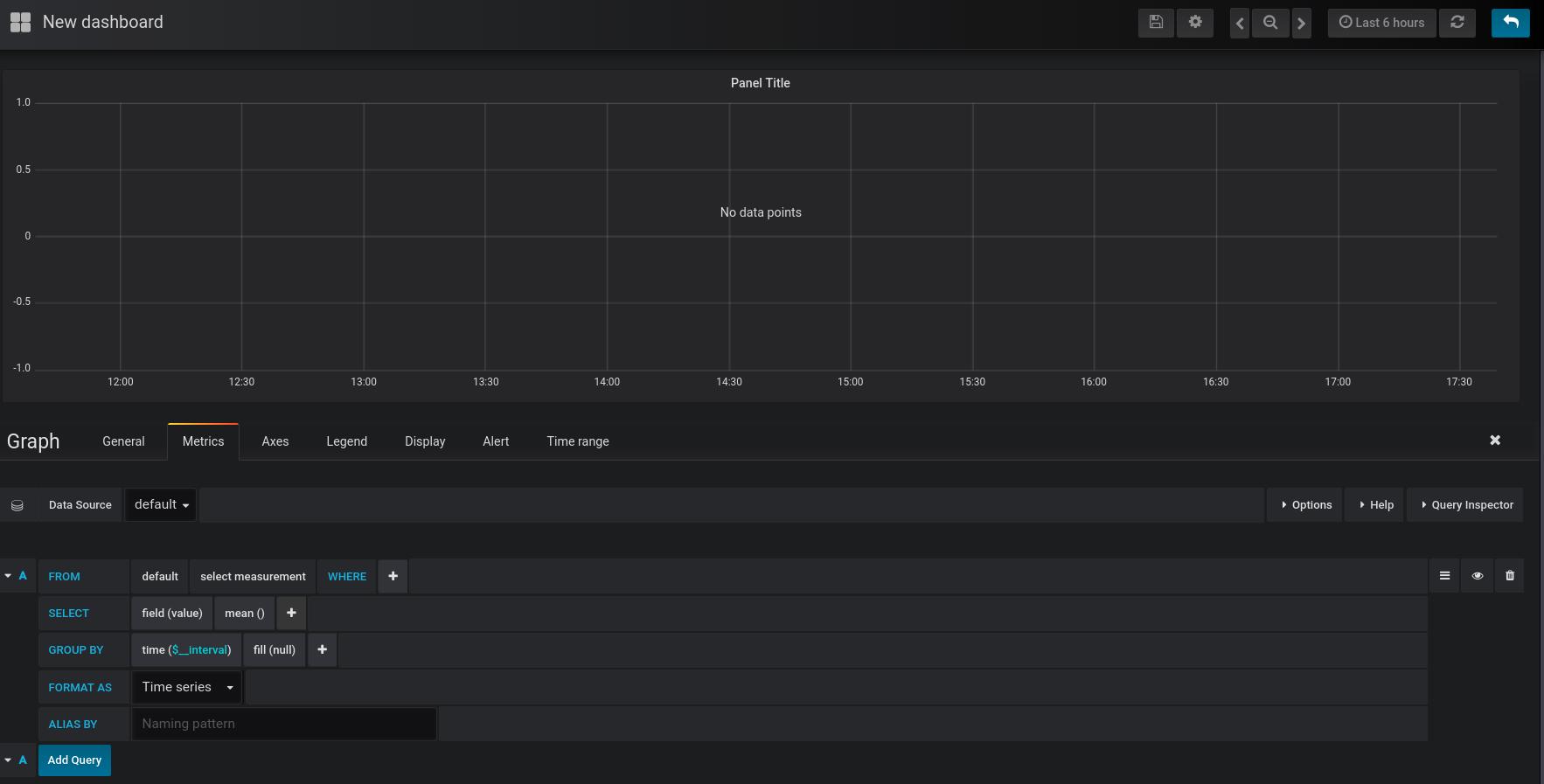
 从上图中可以发现:
从上图中可以发现:
- 中间板块是最后的数据展示
- 下面是数据的设置项
- 右上角是展示时间的设置板块,在这里可以选择要展示多久的数据
7.2.1 配置数据
- 在 Data Source 中选择刚刚在配置数据源的时候配置的 NAME 字段,而不是 database 名。
- 接着在下面选择要展示的数据。看着就很熟悉是不是,完全是 sql 语句的可视化。同时,当我们的数据放到相关的字段上的时候,双击,就会把可以选择的项展示出来了,我们要做的就是直接选择即可;
- 设置右上角的时间,则可以让数据实时进行更新与展示
因为下面的配置实质就是 sql 查询语句,所以大家按照自己的需求,进行选择配置即可,当配置完以后,就可以在中间的面板里面看到数据了。
8. 总结
到这里,本篇文章就结束了。其中,对于 Grafana 的操作我没有介绍的很详细,因为本篇主要讲的是怎么利用这几个工具完成我们的任务。 同时,里面的功能确实很多,还有可以安装的插件。我自己目前还是仅仅对于用到的部分比较了解,所以大家可以查询官方的或者别的教程资料来对 Grafana 进行更深入的了解,制作出更加好看的可视化作品来。 最后,关注公众号,回复 “可视化” 即可获取本文代码哦
来源:https://cuiqingcai.com/6217.html



