根据业务需要,在上传文件前我们要读取文件的md5值,将md5值传给后端用作秒传和断点续传文件的唯一标识。那么前端就需要使用js获取文件的md5值,对于普通小文件可以很轻松的读取文件md5值,而超大文件的md5值是如何快速的获取到的呢?
超大文件如何计算md5值?
前面的文章我们了解了分片上传,解决了大文件和超大文件web上传的超时的问题。
这里我们说的超大文件一般值1G+的文件,对于超大文件,我们不应该一次性的读取文件,这样的话有可能浏览器直接爆了。我们借助分片上传的概念,一片一片的读取文件,即每次读取一个分片内容chunk,之后再进行下一个分片内容继续计算,也就是读一片算一片,这样文件读取完毕,md5的值也就计算好了,同时整个计算过程占有内存也比一次性读取文件要低低多。
使用spark-md5计算本地文件md5
spark-md5.js号称是最适合前端最快的算法,能快速计算文件的md5。
快速安装:
npm install --save spark-md5在组件中使用spark-md5时先引入:
import SparkMD5 from 'spark-md5';spark-md5提供了两个计算md5的方法。一种是用SparkMD5.hashBinary() 直接将整个文件的二进制码传入,直接返回文件的md5。这种方法对于小文件会比较有优势——简单而且速度超快。
另一种方法是利用js中File对象的slice()方法(File.prototype.slice)将文件分片后逐个传入spark.appendBinary()方法来计算、最后通过spark.end()方法输出md5。很显然,此方法就是我们前面讲到的分片计算md5。这种方法对于大文件和超大文件会非常有利,不容易出错,不占用大内存,并且能够提供计算的进度信息。
以上两种方法在spark-md5.js项目主页都有实例代码,本文主要讲第二种方法,即对超大文件计算的md5值。
vue-simple-uploader中添加“计算md5”状态
在上传文件前,需要检查文件状态,计算文件md5值。在上传列表中,其实是暂停状态,而我们不希望用户看到是暂停状态,我们应该友好的告诉用户正在计算md5,或者正在预处理文件,准备上传的状态。
从前几篇文章中,我们已经了解vue-simple-uploader在上传时会返回几种状态,如:上传中…、暂停、上传成功等状态。但并没有对自定义状态提供很好的接口。人们想法设法将类似计算md5的状态显示在上传列表中,在github上也跟作者提过,但好像没有得到更好的解决,无奈我翻看了一下作者的源码,fork下来,稍微做了几处改动,得到以下效果:

并且对原列表样式和图标做了修改,如果你已经安装好了vue-simple-uploader,直接下载:https://github.com/lrfbeyond/vue-uploader/blob/master/dist/vue-uploader.js,替换你的项目下\node_modules\vue-simple-uploader\dist\vue-uploader.js,然后再重新npm run dev即可。
我们在组件调用时可以定义状态,其中cmd5表示的是正在计算md5。
statusTextMap: {
success: '上传成功',
error: '上传出错了',
uploading: '上传中...',
paused: '暂停',
waiting: '等待中...',
cmd5: '计算md5...'
},
fileStatusText: (status, response) => {
return this.statusTextMap[status];
},
计算文件md5
在选择文件准备上传时,触发onFileAdded(),先暂停上传,把md5计算出来后再上传。
暂停上传需要在uploader组件中设置:autoStart="false"即可。
methods: {
onFileAdded(file) {
// 计算MD5
this.computeMD5(file);
},
computeMD5(file) {
...
}
}
根据spark-md5.js官方的例子,我们设置分片计算,每个分片2MB,根据文件大小可以计算得出分片总数。
然后设置文件状态为计算md5,即file.cmd5 = true;。
接着一片片的一次读取分片信息,最后由spark.end()计算得出文件的md5值。
得到md5值后,我们要将此文件的md5值赋值给file.uniqueIdentifier = md5;,目的是为了后续的秒传和断点续传作为文件的唯一标识传给后端。
最后取消计算md5状态,即file.cmd5 = false;,并且立马开始上传文件:file.resume();
//计算MD5
computeMD5(file) {
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,
chunkSize = 2097152, //2MB
chunks = Math.ceil(file.size / chunkSize),
currentChunk = 0,
spark = new SparkMD5.ArrayBuffer(),
fileReader = new FileReader();
let time = new Date().getTime();
file.cmd5 = true; //文件状态为“计算md5...”
fileReader.onload = (e) => {
spark.append(e.target.result); // Append array buffer
currentChunk++;
if (currentChunk < chunks) {
console.log(`第${currentChunk}分片解析完成, 开始第${currentChunk +1} / ${chunks}分片解析`);
loadNext();
} else {
console.log('finished loading');
let md5 = spark.end(); //得到md5
console.log(`MD5计算完成:${file.name} \nMD5:${md5} \n分片:${chunks} 大小:${file.size} 用时:${new Date().getTime() - time} ms`);
spark.destroy(); //释放缓存
file.uniqueIdentifier = md5; //将文件md5赋值给文件唯一标识
file.cmd5 = false; //取消计算md5状态
file.resume(); //开始上传
}
};
fileReader.onerror = () => {
console.warn('oops, something went wrong.');
file.cancel();
};
let loadNext = () => {
let start = currentChunk * chunkSize,
end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize;
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end));
};
loadNext();
},
选择文件后,先计算文件md5值:
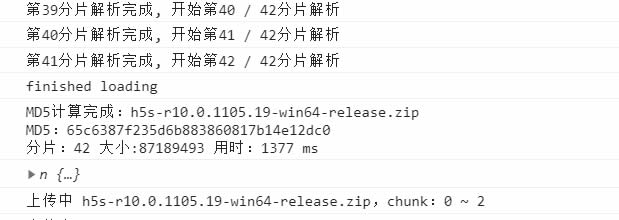
我们看到1个约83MB的文件,计算md5用时1.3秒。
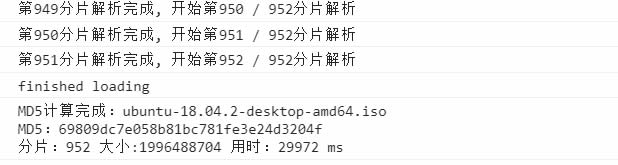
而继续测试发现,1个约2GB的大文件,用时约29秒,我的电脑上8G内存,这个计算文件md5的速度是相当给力的了。
源码已经提交到github上了,请前往下载:https://github.com/lrfbeyond/fast-uploader