
本文 GitHub https://github.com/Jack-Cherish/PythonPark 已收录,有技术干货文章,整理的学习资料,一线大厂面试经验分享等,欢迎 Star 和 完善。
一、人脸识别
人脸识别是一门比较成熟的技术。
它的身影随处可见,刷脸支付,信息审核,监控搜索,人脸打码等。
更多的时候,它是方便了我们的生活,足不出户,就可以实现各种 APP 的实名认证,信息审核。
一些公司,也都有对内部员工开放的刷脸支付系统,不用带手机,不用带工卡,带着一张或美丽或帅气的脸庞,就可以在公司内部「买买买,刷刷刷」。
二、人脸打码
除了这些常规操作,还可以对视频里的特定人物进行打码。
仝卓自爆高考作弊,可谓"教科书"级别的"仝"归于尽的坑爹教程。
为避免风险,《快乐大本营》反应迅速,对仝卓出现的画面进行了打码处理。

这「任性」的打码方式,简单粗暴。
对于视频,人工后期的逐帧处理,打码任务无疑是个「体力活」。
但如果结合脸识别技术,那这个任务就会简单很多。
本文从原理出发,讲解人脸识别技术的视频打码应用。
过滤视频的敏感人物,就这么简单!
三、人脸识别技术
人脸识别技术包涵了多种算法,整个流程大致如下:
- 使用检测技术,检测出人脸位置。
- 使用 landmark 技术,检测出人脸关键点。
- 根据人脸位置和人脸关键点,裁剪出人脸区域,并根据关键点将人脸图片进行矫正,得到「标准脸」。
- 计算「标准脸」的人脸特征向量。
- 与「人脸库」的人脸特征向量比对,计算向量的距离,找到最接近的人,输出人脸识别结果。
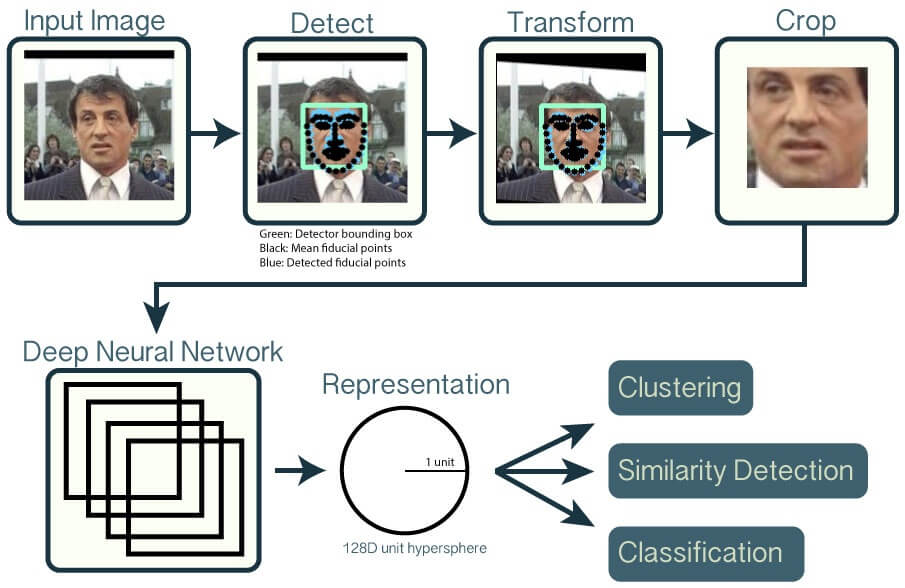
1、人脸检测
输入:原始的可能含有人脸的图像。
输出:人脸位置的 bounding box。
这一步一般我们称之为“人脸检测”(Face Detection),人脸检测算法,可以使用的库有很多,例如 OpenCV、dlib、face_recognition、RetianFace、CenterFace 等等。
太多了,数不过来。
当然,自己用 yolo 、ssd 这类经典的检测算法,自己实现一个也是可以的。
2、人脸裁剪及矫正
输入:原始图像 + 人脸位置 bounding box。
输出:“校准”过的只含有人脸的图像。
这一步需要使用 landmark 算法,检测人脸中的关键点,然后根据这些关键点对人脸做对齐校准。
所谓的关键点,就是下图所示的绿色的点,通常是眼角的位置、鼻子的位置、脸的轮廓点等等。

有了这些关键点后,我们就可以把人脸“校准”,或者说是“对齐”。
解释就是原先人脸可能比较歪,这里根据关键点,使用仿射变换将人脸统一“摆正”,尽量去消除姿势不同带来的误差。这一步我们一般叫 Face Alignment 。
3、人脸特征
输入:校准后的单张人脸图像。
输出:一个向量表示。
这一步就是使用深度卷积网络,将输入的人脸图像,转换成一个向量的表示。这个向量就是人脸的特征,例如:
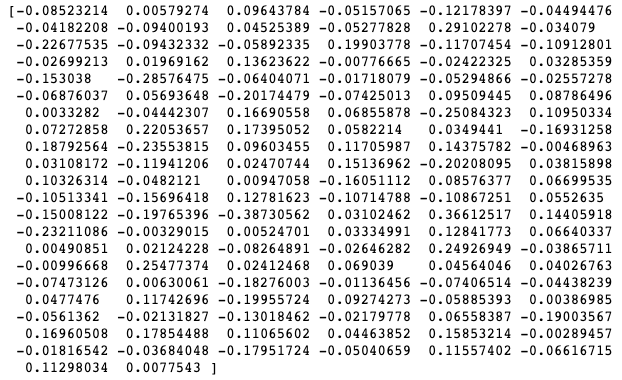
这密密麻麻的 128 维的向量,就是一张人脸的特征,你也可以叫做人脸的编码。
提取特征这种事,卷积神经网络很在行。

举个例子,VGG16 是深度学习中一个比较简单的基本模型。
输入卷积神经网络的是图像,经过一系列卷积后,全连接分类得到类别概率。
整个过程是这样的:

其实,卷积神经网络不断的进行卷积,下采样,这就是一个提取特征的过程,最后通过全链接层得到类别概率。
人脸特征提取,我们也可以这么操作。我们可以去掉全连接层,用计算的特征(一般就是卷积层的最后一层,e.g. 图中的conv5_3)来当作提取的特征进行计算。
与分类任务不同的是,最后使用的 loss 损失函数是不同的。
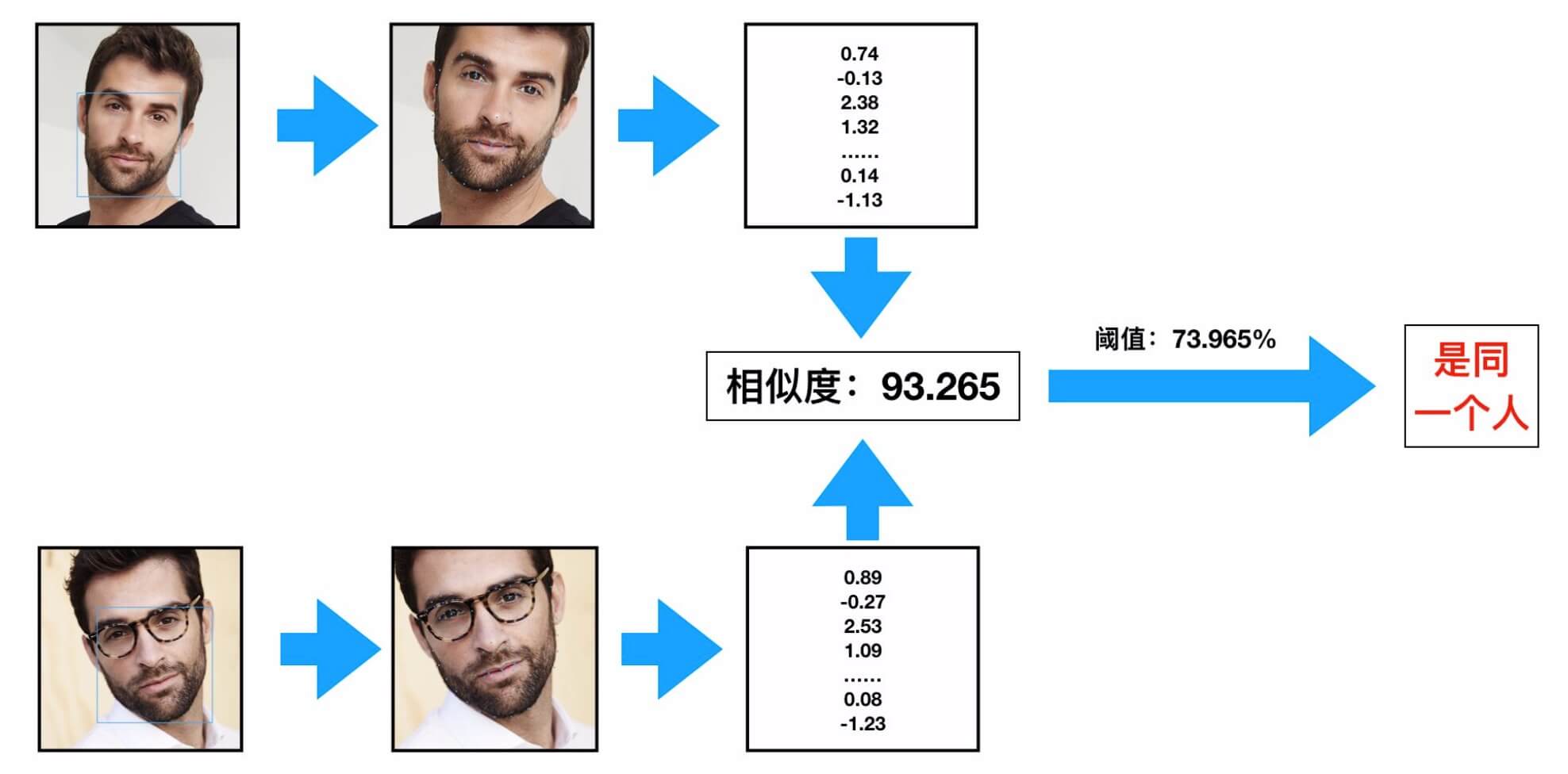
在理想的状况下,我们希望“向量表示”之间的距离就可以直接反映人脸的相似度:
- 对于同一个人的人脸图像,对应的向量的欧几里得距离应该比较小。
- 对于不同人的人脸图像,对应的向量之间的欧几里得距离应该比较大。
所以,每个人脸的类别中心,应该尽可能远一些,这样才能用于区别不同的人。
人脸常用的 loss 有 center loss 、 arcface loss 等。
人脸识别类似于,细粒度的分类。
训练过分类任务的,应该都知道。
训练人和猪的二分类,很好训练,因为人和猪的特征差别很明显。
但训练男人和女人的二分类,就要难一些,因为男人和女人的特征很相近。
为了更好区分男人和女人,就需要使用类别中心间距大的损失函数。
人脸识别,更是一种细粒度的区分,都是人,但你要区分出张三、李四、王二麻。
4、人脸识别
人脸识别,一般是需要建立一个「检索库」。
简单解释一下,我们要识别张三、李四、王二麻。
那么,我们就要选张三、李四、王二麻每个人的 10 张(自己定)图片。
然后使用我们训练好的人脸特征模型,提取每个人的人脸特征。
这样每个人,就都有 10 个人脸特征了,这就是一个「检索库」。
需要识别的图片,提取人脸特征后,依次与检索库已有的人脸特征去比对,投票选出最接近的人。
四、人脸打码
人脸识别技术原理清楚了,我们就可以使用这个技术,给仝卓打码。
可以看到,人脸识别技术涉及到的算法较多,自己依次实现是需要时间的。
但这,难不倒身为优秀「调包侠」的我。
开源的第三方库有很多,比如 face_recognition。
里面集成了人脸检测、人脸识别等接口。
我们先看下今天的任务。
使用人脸识别技术,对这一小段视频,给仝卓的人脸进行打码。
整理一下思路:
首先,我们使用 opencv 这类的程序处理视频,只能处理画面,不能处理声音。
所以,需要先将音频保存,再将处理好的视频和音频进行合成,这样既保证了画面打码,又保证了声音还在。
这块可以使用 ffmpeg 实现。
安装好 ffmpeg 并配置好环境变量。
ffmpeg 下载地址:https://ffmpeg.zeranoe.com/builds/
编写如下代码:
import subprocess
import os
from PIL import Image
def video2mp3(file_name):
"""
将视频转为音频
:param file_name: 传入视频文件的路径
:return:
"""
outfile_name = file_name.split('.')[0] + '.mp3'
cmd = 'ffmpeg -i ' + file_name + ' -f mp3 ' + outfile_name
subprocess.call(cmd, shell=True)
def video_add_mp3(file_name, mp3_file):
"""
视频添加音频
:param file_name: 传入视频文件的路径
:param mp3_file: 传入音频文件的路径
:return:
"""
outfile_name = file_name.split('.')[0] + '-f.mp4'
subprocess.call('ffmpeg -i ' + file_name
+ ' -i ' + mp3_file + ' -strict -2 -f mp4 '
+ outfile_name, shell=True)
视频转音频,视频加音频的函数写好了,接下来,我们写视频自动打码的程序。
首先,安装 face_recognition。
python -m pip install face_recognition
face_recognition 有详细的 API 文档:
https://face-recognition.readthedocs.io/en/latest/face_recognition.html
我们先将要处理的视频保存到本地:
https://cuijiahua.com/wp-content/uploads/2020/07/cut.mp4
然后就可以使用 opencv 读取视频检测画面的每一张人脸。
import cv2
import face_recognition
import matplotlib.pyplot as plt
# %matplotlib inline # 在 jupyter 中使用的时候,去掉注释
cap = cv2.VideoCapture('cut.mp4')
ret, frame = cap.read()
if ret:
face_locations = face_recognition.face_locations(frame)
for (top_right_y, top_right_x, left_bottom_y,left_bottom_x) in face_locations:
cv2.rectangle(frame, (left_bottom_x,top_right_y), (top_right_x, left_bottom_y), (0, 0, 255), 10)
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_RGB2BGR))
plt.show()
运行效果:

这样,对画面中检测到的每张人脸,进行人脸识别,是仝卓,那就打码。
打码图片,咱也用个简单粗暴的。

打码图片下载地址:
https://static.shanhubei.com/shb/cuijiahua/mask.jpg
将 mask.jpg 保存到本地。
再截取一张仝卓的人脸图片,作为对比库,当然多张也是可以的,这里用一张就够了。

我们选择这张图片,图片下载地址:
https://static.shanhubei.com/shb/cuijiahua/tz.jpg
将图片下载到本地,编写如下代码,就可以提取人脸的特征。
import face_recognition
known_image = face_recognition.load_image_file("tz.jpg")
biden_encoding = face_recognition.face_encodings(known_image)[0]
print(biden_encoding)
运行结果:
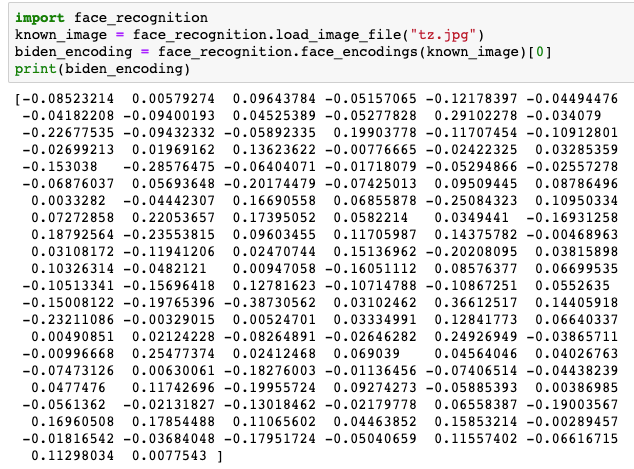
可以看到使用几行代码,就可以提取 128 维的人脸特征。
整体流程是:
- 使用 ffmpeg 保存音频
- 处理视频,给仝卓打码。
- 为处理好的视频添加音频。
直接看代码。
# Author : Jack Cui
# Website: https://cuijiahua.com/
import cv2
import face_recognition
import matplotlib.pyplot as plt
# %matplotlib inline # 在 jupyter 中使用的时候,去掉注释
import subprocess
import os
from PIL import Image
def video2mp3(file_name):
"""
将视频转为音频
:param file_name: 传入视频文件的路径
:return:
"""
outfile_name = file_name.split('.')[0] + '.mp3'
cmd = 'ffmpeg -i ' + file_name + ' -f mp3 ' + outfile_name
print(cmd)
subprocess.call(cmd, shell=True)
def video_add_mp3(file_name, mp3_file):
"""
视频添加音频
:param file_name: 传入视频文件的路径
:param mp3_file: 传入音频文件的路径
:return:
"""
outfile_name = file_name.split('.')[0] + '-f.mp4'
subprocess.call('ffmpeg -i ' + file_name
+ ' -i ' + mp3_file + ' -strict -2 -f mp4 '
+ outfile_name, shell=True)
def mask_video(input_video, output_video, mask_path='mask.jpg'):
# 打码图片
mask = cv2.imread(mask_path)
# 读取视频
cap = cv2.VideoCapture(input_video)
# 读取视频参数,fps、width、heigth
CV_CAP_PROP_FPS = 5
CV_CAP_PROP_FRAME_WIDTH = 3
CV_CAP_PROP_FRAME_HEIGHT = 4
v_fps = cap.get(CV_CAP_PROP_FPS)
v_width = cap.get(CV_CAP_PROP_FRAME_WIDTH)
v_height = cap.get(CV_CAP_PROP_FRAME_HEIGHT)
# 设置写视频参数,格式为 mp4
size = (int(v_width), int(v_height))
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
out = cv2.VideoWriter(output_video,fourcc, v_fps, size)
# 已知人脸
known_image = face_recognition.load_image_file("tz.jpg")
biden_encoding = face_recognition.face_encodings(known_image)[0]
# 读取视频
cap = cv2.VideoCapture(input_video)
while(cap.isOpened()):
ret, frame = cap.read()
if ret:
# 检测人脸
face_locations = face_recognition.face_locations(frame)
# 检测每一个人脸
for (top_right_y, top_right_x, left_bottom_y,left_bottom_x) in face_locations:
unknown_image = frame[top_right_y-50:left_bottom_y+50, left_bottom_x-50:top_right_x+50]
unknown_encoding = face_recognition.face_encodings(unknown_image)[0]
# 对比结果
results = face_recognition.compare_faces([biden_encoding], unknown_encoding)
# 是仝卓,就将打码贴图。
if results[0] == True:
mask = cv2.resize(mask, (top_right_x-left_bottom_x, left_bottom_y-top_right_y))
frame[top_right_y:left_bottom_y, left_bottom_x:top_right_x] = mask
# 写入视频
out.write(frame)
else:
break
if __name__ == '__main__':
# 将音频保存为cut.mp3
video2mp3(file_name='cut.mp4')
# 处理视频,自动打码,输出视频为output.mp4
mask_video(input_video='cut.mp4', output_video='output.mp4')
# 为 output.mp4 处理好的视频添加声音
video_add_mp3(file_name='output.mp4', mp3_file='cut.mp3')
程序有详细的注释,最终生成的视频会保存为 output-f.mp4,让我们看下效果吧。
效果还不错吧?
五、最后
face_recognition 无论是检测还是识别的效果一般,想实现更强大、更稳定的自动打码效果,就需要自己有针对的优化订制了。
PS:文中出现的所有代码,均可在我的 github 上下载,欢迎 Follow、Star:点击查看
![]()
来源:
https://cuijiahua.com/blog/2020/07/dl-23.html



