
一、前言
最近一直在参加各种面试,感觉自己面试表现很弱鸡,虽然已经有了点offer,但跟那些offer收割机比起来,差得太远。本篇文章记录了自己在面试过程中被问到的各种问题以及一些经验之谈。对于后续碰到的一些面试题,我会持续更新。
我选择岗位的标准是,找各个公司最适合我的实习岗位,有就投,没有就pass,因此我投递的岗位有些多样,主要投递的岗位:算法工程师、机器学习/深度学习工程师、数据挖掘工程师。
参加过的面试形式有:电话面、视频面、现场面。
对了,找面试期间,如果你的来电标有房产中介之类标识,也要接起来,不要直接挂断,因为没准这就是你面试官的副业(尴尬脸)。
二、经验总结
参加面试各种不顺,深感自己的弱项在于数据结构掌握不行,剑指offer刷了一遍,怎奈脑子不够用,总是忘记,还需继续努力才是。
刚开始面试的时候,遇到了各种问题,也办了一些傻事。此处总结下,说下自己的感受:
认真思考
刚开始参加面试的时候,很不自信。远程电话面试的时候,面对面试官的一个问题,我的第一反应是这个问题在哪看过,网上是怎么说的,甚至是在哪能找到答案。当时的我忽略了思考这个问题本身,而去想从何处能找到所谓的正确答案,自己的这一问题是准备不充分、不自信、紧张共同造成的结果。其实,如果认真的思考问题本身,答案并不难想到,而我往往是撂下电话,自己认真思考一下,然后悔恨不已:哇,刚才怎么没有想到!所以一句话:面对面试官的问题,一定要自己认真思考问题本身,自信一些,说出自己的想法,如果碰到耐心的面试官,他会一步一步引导你的。
做好准备
刚开始我是“佛系”面试,一切随缘,真的一点不准备,也不知道自己应该看啥,然后面试了还蒙逼,明明有些不自信,还这么浪,可想而知,面试结果也很惨,二连跪,三连跪,跪得我都快站不起来了。当然,如果是真大牛,“佛系”面试也可以,怎奈我是一个渣硕,准备还是需要好好做的,因此决定痛改前非,重新做人。经过一段时间的准备,终于有些思路了,我认为需要着重准备以下几点:自我介绍、数据结构、简历项目、岗位需求。
- 自我介绍:这个是最好准备的东西了,根据自己的实际经历,组织好语言即可。有些面试官会问,或者刚开始面试的时候,面试官正在看你简历时,你可以主动提:那我先做下简单的自我介绍吧。
- 数据结构:数据结构不是说我刷过剑指offer就算准备好了,应该在面试之前,把常规的数据结构题目过一遍,比如八大排序算法默写一遍,不要在IDE里调试着写,在纸上写或者在文本编辑器中写。因为面试让你写的时候,就是如此。个人感觉,面试的时候,在线编程出的题不会很难,无非就是字符串类型、数组类型、二叉树类型、堆栈类型、链表类型,把这几种常见类型题都过一遍,比如两个单链表如何判断是否相交、知道有相交怎么找到这个交点诸如此类的问题,都自己写一遍。剩下的拔高题可以适当看一下,然后就是临场发挥和积累了。
- 简历项目:面试官问的一些问题往往都是针对项目经历问的,比如我写了基于嵌入式平台的目标检测系统,那么面试官就会问yolo、ssd原理可以说一下吗?yolo v2做出了哪些改进?针对自己简历上写的项目,好好想一想可能出哪些问题?自问自答走一波。
- 岗位需求:这个就需要我们针对岗位要求进行准备了,比如对于深度学习岗位,会问下神经网络基础,卷积核是怎么计算的?卷积层、全连阶层都有什么作用?你会用哪些深度学习框架,可以简述下使用流程吗?你认为深度学习和传统机器学习本质上有什么不同?对于这些问题,我们都可以提前准备,面试前一个小时,好好过一遍,会有意想不到的收获的。
时刻准备
有些公司电话说不定什么时候就打进来了,可能投递简历半个月了,你都忘记了。本以为是直接约个面试时间,结果上来直接面试。当然此时,可以说下自己现在不方便,可不可以另约时间。但是心里总会有疑虑:哇,这样到时候他会不会忘了?人到时候满了,自己进不去了?诸如此类的想法。其实,大多时候是没有问题的,不必有这些想法。不过,也不排除罕见的个别情况。所以,为了完全避免这些忧虑,时刻做好面试准备,保持电话时刻畅通是很有必要的。
尽量内推
内推很重要,如果没有内推,那么需要走简历筛选流程,就是HR从简历池把你的简历捞出来,如果没有捞出来,也就是没有相中你的简历,很可能你连个面试机会都没有,直接把你pass了。但是如果有内推,就会好很多。而且内推可以走提前批,大厂都有这些流程,意思就是不用等后面的统一笔试,直接面试。从哪找内推呢?
- 通过师兄、师姐;
- 有的公司没有师兄师姐在怎么办?可以通过各个QQ群,比如一些春招内推群、秋招内推群;也可以通过各大学校的BBS,对于外校不能访问的BBS,例如北邮人,可以找同学借帐号,或者通过镜像站进入;还有就是公众号了,现在好多公众号都在做这个方面的东西,比如:校招导师、校招日历、内推军等。校招导师不用发朋友圈广告就能获得内推邮箱,其他需要转发,自行斟酌吧。
- 最后就是一些学习群,比如机器学习相关的大群,偶尔也会有一些内推信息。
不要着急
这一点我感觉也很重要,别上来就投BAT大厂的岗位,先试试其他公司,试试水。不过话又说回来,其实一些初创公司反而面试可能会更难,因为BAT这些大厂出题都是有迹可循,而一些初创公司说不定考你什么题,并且可能岗位要求比大厂还高。
值得注意的一点是,如果对于部门不了解,一定要好好了解一番,不要急着投递简历,咨询咨询别人,选择部门也是一门学问。
同时,比如一些笔试,如果没有信心,可以等一等,等第一波人做完了,咨询一下,至少什么类型的题你是能知道的。
博客、Github没那么重要
曾经以为有个好的博客,牛的Github项目,就能有一些加分。现在发现,这个就要看面试官怎么看了,面试官感觉好,就有用。如果面试官感觉没用,那就作用不大。
个人感觉,这些东西只能算作一块好看一点的敲门砖。如果把没有这些的简历比作一个没用使用美颜和滤镜的摄像机拍下的砖头,那么有这些东西的简历就是开了美颜和滤镜的磨了皮的砖头。好看了一点,但是面试的时候,还是要看你的本质,需要好好准备内功才是。
尽管用处不是很多,我依然很喜欢做这些工作。因为我一直感觉自己脑子不够用,需要靠这些笔记回顾自己所学。别人看过的东西,等到用到的时候可以第一时间想起来;但是我有时候真的想不起来,但是我可以想起我在哪写过,我可以第一时间找到这篇自己写的文章,并且迅速回顾,然后用起来。所以,天赋不同,注定我要靠这种方式去弥补自己的不足。
除此之外,我感觉另一个好处就是,会有一些人主动联系你,帮你内推吧。当然,后续的面试情况还是要看你自己的。
运气也很重要
感觉面试也很看运气,与其说是运气,不如说是面试技巧。感觉这个挺玄学的,不过它确实存在,你跟面试官很match,问的题目刚好是自己都会的,那么恭喜,这轮面试你就轻松过去了。不能否认运气的存在,更不能全靠运气,自身实力过硬,一切OK。
三、问题汇总
我遇到的问题,总共可分为七类:数学题、计算机基础、数据结构、机器学习相关、深度学习相关、项目相关、业务场景。
项目相关是根据个人简历问的,每个人的项目经历都不同,只需要根据事情阐述即可,此文不做记录,本文主要记录另外五类问题。
数学题:
面试的时候确实问到了一些数学题,感觉这里也是值得补习一下的,特别是算法岗。不过对于我被问到的数学知识我是真忘记了,因为有的名词都没听过,直接蒙逼…
好在面试的时候,这方面的考点不是很多。
计算机基础:
对于我找的方向来说,一般都会问一些linux基础,比如常用linux指令,这个如果平时经常用linux的话,问题不大。如果没有这方面基础的,就需要提前学一学了。还有就是会问一下关于你熟悉的计算机语言的基础知识,比如我说我更熟悉python,那么面试官可能就会问一些关于python基础的问题。
总结下我曾被问到的相关问题:
1、进程和线程的区别?
答:进程拥有一个完整的虚拟地址空间,不依赖于线程而独立存在;反之,线程是进程的一部分,没有自己的地址空间,与进程内的其他线程一起共享分配给该进程的所有资源。
比如:开个QQ,开了一个进程;开了迅雷,开了一个进程。在QQ的这个进程里,传输文字开一个线程、传输语音开了一个线程、弹出对话框又开了一个线程。所以运行某个软件,相当于开了一个进程。在这个软件运行的过程里(在这个进程里),多个工作支撑的完成QQ的运行,那么这“多个工作”分别有一个线程。所以一个进程管着多个线程。通俗的讲:“进程是爹妈,管着众多的线程儿子”。
参考自:https://www.zhihu.com/question/25532384
2、为什么说python的线程是伪线程?
答:在python的原始解释器CPython中存在着GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限制线程对共享资源的访问,直到解释器遇到I/O操作或者操作次数达到一定数目时才会释放GIL。
所以,虽然CPython的线程库直接封装了系统的原生线程,但CPython整体作为一个进程,同一时间只会有一个线程在跑,其他线程则处于等待状态。这就造成了即使在多核CPU中,多线程也只是做着分时切换而已。
参考自:https://www.zhihu.com/question/23474039
3、python的append和extend有什么区别?
答:extend()接受一个列表参数,把参数列表的元素添加到列表的尾部,append()接受一个对象参数,把对象添加到列表的尾部。
例如:
a = [1,2] b = [1,2,3] a.append(b) print(a)
输出结果为:
[1, 2, [1, 2, 3]]
而:
a = [1,2] b = [1,2,3] a.extend(b) print(a)
输出结果为:
[1, 2, 1, 2, 3]
4、linux下创建定时任务使用什么指令?
答:可以使用crontab命令。
5、数据库Mysql和MongoDB的区别?
答:Mysql是关系型数据库,MongoDB是文档型数据库。MongoDB占用空间大,典型的用空间换时间原则的类型。Mysql相对成熟,MongoDB较为年轻。
6、你知道的加解密算法有哪些?
答:AES(对称加密)、RSA(非对称加密)、MD5(Hash算法)等。
数据结构:
个人感觉数据结构最重要,面试过一些公司,五花八门什么题都有,但是唯一统一,都考的就是数据结构基础了。但是考法不同,区别在于有的让说思路,有的让在线写代码。
私以为,复习的方法应该是:审题->思考->表达->码字。
首先,审题很重要无需废话,拿到题目,我们需要认真思考一番。然后就需要组织语言,把自己所想表达清楚。别小看这一个步骤,组织语言表达清楚很重要。一些公司都是先让说思路,再让写代码的,甚至是只说思路。所以,在复习的时候,把每道题的思路想清楚,说明白很重要。最后,我们再将自己的想法写成代码。
其实,这部分的数据结构基础题,只要《剑指Offer系列刷题笔记汇总》这些题目都掌握好,就足以应付,不会出太难的题目难为人,都是常规题。
下面对一些常见题型进行汇总,这些也是我面试时,真实被问到的题以及相关扩展题。
链表:
1、找出单链表的倒数第K个元素(仅允许遍历一遍链表)
答:使用指针追赶的方法,定义一个fast指针和一个slow指针,fast指针先走K步,然后fast和slow同时继续走。当fast指针走到链表尾部时,slow指向的位置就是倒数第K个元素。注意:要考虑链表长度应该大于K。参考:剑指Offer(十四):链表中倒数第k个结点
2、找出单链表的中间元素(仅允许遍历一遍链表)
答:使用指针追赶的方法,定义一个fast指针和一个slow指针,两个指针同时走,fast指针每次走两步,slow指针每次走一步。当fast指针到链表尾部时,slow指针指向的就是链表的中间元素。
3、判断单链表是否有环?
答:使用指针追赶的方法,定义一个fast指针和一个slow指针,两个指针同时走,fast指针每次走两步,slow指针每次走一步。如果有环,则两者会相遇;如果没有环,fast指针会遇到NULL退出。
4、已知单链表有环,如何知道环的长度?
答:使用指针追赶的方法,定义一个fast指针和一个slow指针,两个指针同时走,fast指针每次走两步,slow指针每次走一步,找到碰撞点。然后使用slow指针,从该碰撞点开始遍历,绕着走一起圈,再次回到该点,所走过的结点数就是环的长度。
5、如何找到环的入口结点?
答:先使用题4的方法,计算出环的长度。然后重新从头结点开始遍历,定义定义一个fast指针和一个slow指针,fast指针先走l(环的长度)步,然后两个指针以相同的速度在链表上向前移动,直到它们再次相遇,那么这个相遇点即为环的入口结点。参考:剑指Offer(五十五):链表中环的入口结点
6、判断两个无环单链表是否相交?
答:一旦两个链表相交,那么两个链表从相交节点开始到尾节点一定都是相同的节点。所以,如果他们相交的话,那么他们最后的一个节点一定是相同的,因此分别遍历到两个链表的尾部,然后判断他们是否相同。
7、如何知道两个单链表(可能有环)是否相交?
答:根据两个链表是否有环来分别处理,若相交这个环属于两个链表共有
(1)如果两个链表都没有环,如题6所示方法。
(2)一个有环,一个没环,肯定不相交。
(3)两个都有环。在A链表上,使用指针追赶的方法,找到两个指针碰撞点,之后判断碰撞点是否在B链表上。如果在,则相交。
8、寻找两个相交链表的第一个公共结点。
答:我们也可以先让把长的链表的头砍掉,让两个链表长度相同,这样,同时遍历也能找到公共结点。此时,时间复杂度O(m+n),空间复杂度为O(MAX(m,n))。参考:剑指Offer(三十六):两个链表的第一个公共结点
9、反转链表。
答:我们使用三个指针,分别指向当前遍历到的结点、它的前一个结点以及后一个结点。在遍历的时候,交换当前结点的尾结点和前一个结点的。参考:剑指Offer(十五):反转链表指
数组:
1、给定一个数组(非递减排序),同时给定一个目标数字,找出这个数字在该数组中第一次出现的位置,如果不存在,返回-1。例如[1,3,5,5,5,5,8,9,13,15],输入5,返回2,输入8,返回6,输入18,返回-1。
答:使用二分查找法即可。
# -*-coding:utf-8 -*- def BinarySearch(input_list, end, value): if end == 0 or value < input_list[0] or value > input_list[-1]: return -1 left = 0 right = end - 1 while left <= right: middle = left + (right - left) // 2 if input_list[middle] >= value: right = middle - 1 else: left = middle + 1 return left if left < end else -1 if __name__ == '__main__': input_list = [1,3,5,5,5,5,8,9,13,15] target = 5 print(BinarySearch(input_list, len(input_list), target))
运行结果如下图所示:

2、给定一个数组,里面有很多数字(乱序),找出其中最大的4个数字。
答:最简单的办法就是先排序再找出最大的四数,这种方法时间复杂度过高。一个更好的方法是使用堆排序,即维护一个存储最大的4个数的最小堆。
解析:这的思想和代码可以参考《剑指Offer(二十九):最小的K个数》,这里仅仅做了一个变形。
3、给定一个整数的数组nums,返回相加为target的两个数字的索引值。假设每次输入都只有一个答案,并且不会使用同一个元素两次。
答:如果这个数组是已经排序的,可以使用头指针和尾指针,我们可以定义一个头指针left,一个尾指针right。left指针指向元素值+right指针指向元素值的和为sum,用sum和target比较。如果sum>target,说明和大了,那么right右指针左移一位,然后重新判断。反之,如果sum<target,说明和小了,那么left左指针右移以为,然后会从新判断。直到找到sum=target的情况。如果没有排序,可以使用使用哈希表,也就是散列表。
解析:如果没有排序,这道题就是Leetcode中的一道题。代码可以参考《Two Sum》。
4、给定一个字符串,找到最长无重复子字符串。
答:定义两个变量longest和left,longest用于存储最长子字符串的长度,left存储无重复子串左边的起始位置。然后创建一个哈希表,遍历整个字符串,如果字符串没有在哈希表中出现,说明没有遇到过该字符,则此时计算最长无重复子串,当哈希表中的值小于left,说明left位置更新了,需要重新计算最长无重复子串。每次在哈希表中将当前字符串对应的赋值加1。
解析:Leetcode中的一道题。代码可以参考《Longest Substring Without Repeating Characters》。
二叉树:
1、给定任意一棵二叉树,假设每个结点之间的距离相等,现从任意叶结点,点燃这颗二叉树,假设结点到结点间的燃烧时间均为1s,问需要多久能烧完整颗二叉树。
答:二叉树燃烧,需要向父结点遍历。此外,因为是燃烧整颗二叉树,所以结点间应该是扩散式的同时燃烧。因此思路是找到点燃的叶结点到另一个结点的最大距离。
代码略。PS:当时在线编程写的也不是很好。
其他:
1、不使用现成的开根号库函数,如何实现开平方根的操作?
答:可以使用二分查找法或者牛顿法。
# -*-coding:utf-8 -*-
def sqrt_binary_search(target):
left = 0
right = target
mid = (left + right) / 2
while abs(mid*mid-target) > 0.000001:
if mid*mid == target:
return mid
elif mid*mid > target:
right = mid
else:
left = mid
mid = (left + right) / 2
return mid
def sqrt_newton(target):
k = target
while abs(k*k-target) > 0.000001:
k = 0.5*(k+target/k)
return k
if __name__ == '__main__':
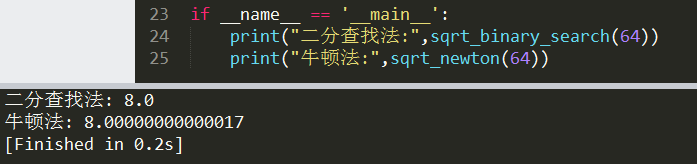
print("二分查找法:",sqrt_binary_search(64))
print("牛顿法:",sqrt_newton(64))
运行结果如下图所示:
2、一个自然序列,从0开始,去掉凡是出现8和9的数,请问去掉后的序列中的第2018个数是多少?
答:这道题只要理解题意就好了,怎奈我当时紧张,感觉答的不好,其实事后仔细一想还是蛮简单的。例如去掉后的序列为:0,1,2,3,4,5,6,7,10,11,12,13,14,15,16,17,20,21,22,23,24,25,26,27,30,31,32,33,34,35,36,37···。通过数字规律,会发现,其实这个就是10进制转8进制,第9个数是10,第17个数是20,第25个数是30。那么,第2018个数是多少?用除八取余法,得3742。而第2018个数,应该是3742-1=3741。
3、EXCEL中,列序是有规律的。A,B,C···,Z,接着是AA,AB,···,AZ,再接着是BA,BB,···,BZ。这样一直循环下去,等到有三位的时候就是从AAA开始。请问,第2018个数对应的序列号是多少?
答:这道题还是进制转换问题,是10进制转26进制。比如第27个数:27除以26为1余1,那么结果就是AA,第53个数:53除以26为2余1,那么结果就是BA。同理,第2018个数:使用除26取余法,得到最终结果为BYP。
机器学习:
1、什么是归一化,归一化的作用是什么?
答:归一化是将数据变为(0,1)之间的小数,主要是为了数据处理方便,把数据映射到0~1范围之内处理,处理起来可以更加便捷快速。归一化的作用是把有量纲表达式变为无量纲表达式,归一化是一种简化计算的方式,即将有量纲的表达式,经过变化,化为无量纲的表达式,成为纯量。同时,提高迭代求解的收敛速度,提高迭代求解的精度。
相应扩展:
深度学习中的归一化应该怎么理解?
答:神经网络学习过程的本质是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另一方面,一旦每批训练数据的分布各不相同,那么网络就要在每次迭代都去学习适应不同的分布,这样会大大降低网络的训练速度,这也正是为什么我们需要对数据进行归一化处理的原因。对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。因此,我们一般会对输入数据进行”白化”除理,使得它的均值是0,方差是1。
2、标准化是什么?
答:数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变化将其数值映射到某个数值区间。
相应扩展:
常见的数据归一化方法有哪些?
答:min-max标准化、z-score标准化等。
对于数据标准化/归一化的详细内容,可以参见:http://blog.csdn.net/pipisorry/article/details/52247379
3、你最熟悉的机器学习算法是什么?可以讲解下SVM原理吗?
答:省略若干字。
解析:这部分内容可以参考我的文章《机器学习实战教程(八):支持向量机原理篇之手撕线性SVM》,我当时面试的时候是先说的线性可分的情况,然后再引入核函数。
4、在推导公式的时候,要向量化,这是什么意思?
答:其实就是将多组数据,放到一个矩阵里,进行矩阵运算。因为如果是一条一条遍历计算参数,需要用到for循环,这样很浪费时间。python的第三方库提供了很好的矩阵计算支持,我们完全可以把多组数据放到一个矩阵里,这样可以实现多组数据同时计算。这个向量化推导,就是根据一条数据计算公式推导出矩阵运算公式,这样可以方便我们写代码。
5、在逻辑回归中,我们使用的是sigmoid函数,知道sigmoid函数吧?
答:知道。
继续问:那么tanh函数和它有什么区别呢?
答:它们的值域不同,sigmoid函数将输出映射到0~1的范围内,而tanh函数将输出映射到-1~1的范围内。同时,它们过零点的值也不同,sigmoid函数的过零点的值为0.5,tanh函数过零点的值为0。当我们更偏向于当激活函数的输入是0时,输出也是0的函数时候,就需要使用tanh函数,而非sigmoid函数。
6、SVM和Logistic的区别?
答:(1)SVM不是概率输出,Logistic Regression是概率输出。也就是说,当一个新样本来了,SVM只会告诉你它的分类,而Logistic Regression会告诉你它属于某类的概率!(2)异常点的鲁棒性问题。当训练样本中存在异常点时,由于Logistic Regression的lost function中有每一个点的贡献,所以某种程度上“削弱了”异常点的贡献。而SVM只需要考虑支持向量,此时支持向量本来就不是很多的情况下,几个异常点就很有可能极大影响SVM的表现。(3)目标函数不同。Logistic Regression使用cross entropy loss,互熵损失。而SVM使用hinge loss,铰链损失。(4)实际问题中,如果数据量非常大,特征维度很高,使用SVM搞不定时,还是用Logistic Regression吧,速度更快一些。
7、常见的损失函数有哪些?
- 铰链损失(Hinge Loss):主要用于支持向量机(SVM) 中;
- 互熵损失 (Cross Entropy Loss,Softmax Loss ):用于Logistic 回归与Softmax 分类中;
- 平方损失(Square Loss):主要是最小二乘法(OLS)中;
- 指数损失(Exponential Loss) :主要用于Adaboost 集成学习算法中;
- 其他损失(如0-1损失,绝对值损失)。
参考自:https://blog.csdn.net/u010976453/article/details/78488279
8、GBDT和XGBOOST的区别有哪些?
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
参考自:https://www.zhihu.com/question/41354392
深度学习:
目标检测算法相关:
1、简述下YOLO算法原理?
答:Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,模型参考自GoogleNet,YOLO的CNN网络将输入的图片分割成SxS的网络,然后每个单元格负责去检测那些中心点落在该格子内的目标。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度,边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征。边界框的大小与位置可以用4个值来表征:(x,y,w,h),其中(x,y)是边界框的中心坐标,而(w,h)是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,而(w,h)预测值是相对于整个图片的宽与高的比例。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。每个单元格需要预测 (B*5+C) 个值。如果将输入图片划分为 S*S 网格,那么最终预测值为 S*S*(B*5+C) 大小的张量。对于PASCAL VOC数据,其共有20个类别,如果使用 S=7,B=2 ,那么最终的预测结果就是 7*7*30大小的张量。
解析:不用慌,只要自己思路清晰,说的连贯,不间断卡壳就行,其实如果面试官不了解这些,他也是听不懂的,但是最好不要瞎说,因为他也会查的,并且可能会抓住其中一点,深入细问,如果问的正好是你瞎编的内容,你就无法自圆其说了。
2、相对于YOLO,YOLO v2有哪些改进?
- 首先,将dropout层去掉,在每个卷积层添加了Batch Normalization,mAP提高了2%;
- 其次,使用高分辨率分类器,将输入分辨率数据有224*224变为448*448,mAP提高了4%;
- 第三,引入anchor boxes来预测bounding boxes,去掉网络中的全连接层。准确率只有小幅度的下降,而召回率则提升了7%,说明可以通过进一步的工作来加强准确率,的确有改进空间;
- 第四,使用维度聚类,本文使用K-means聚类方法训练bounding boxes,可以自行找到更好的boxes宽高维度;同时使用直接位置预测(Direct lacation prediction),将定位预测值归一化,使参数更容易得到学习,模型更加稳定。作者使用Dimension Clusters和Direct location prediction这两项anchor boxes改进方法,mAP获得了5%的提升。
- 第五,增加细粒度特征(Fine-Grained Feature),是模型获得多尺度的适应性,简单添加了一个转移层( passthrough layer),这一层要把浅层特征图(分辨率为26 * 26,是底层分辨率4倍)连接到深层特征图。这样做相当于做了一次特征融合,有利于检测小目标。
- 最后,多尺度训练(Multi-Scale Training),方法就是几次迭代之后就会微调网络,每过10次训练(10 epoch),就会随机选择新的图片尺寸。YOLO网络使用的降采样参数为32,那么就使用32的倍数进行尺度池化{320,352,…,608}。最终最小的尺寸为320 * 320,最大的尺寸为608 * 608。接着按照输入尺寸调整网络进行训练。这种机制使得网络可以更好地预测不同尺寸的图片,意味着同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。
3、深度学习方法与传统机器学习方法的区别是什么?
答:机器学习包括深度学习,深度学习是使用卷积层学习特征,而非像机器学习那样需要人为提取特征,深度学习可以自行学习到更深层次的特征。机器学习方法的各个公式有数学理论推导支持,深度学习方法就像一个黑匣子,缺少数学理论支持。
4、YOLO的损失函数是什么?
答:YOLO算法将目标检测看成回归问题,采用的是均方差损失函数。公式如下图所示:
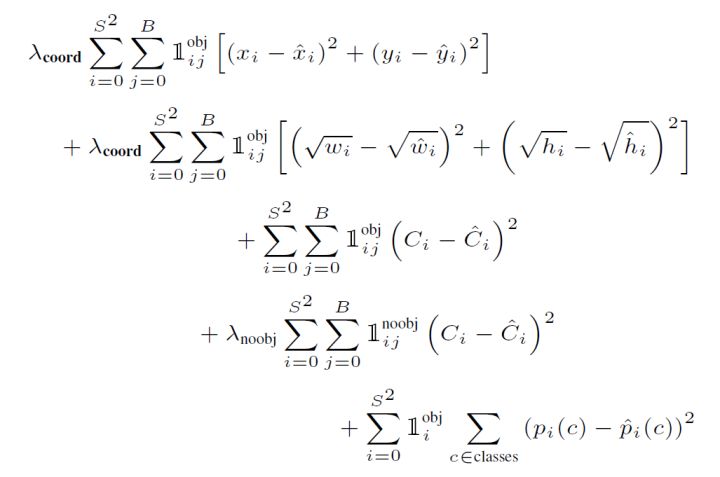
参考自:https://zhuanlan.zhihu.com/p/32525231
业务场景:
这种题目也是常出题目,会给定你一个场景来提问。
1、如果给了你很多数据,这些数据已经标注好,即已经做好分类,现在让你训练出一个模型,用于区分新来的数据属于哪一类,你需要怎么做呢?可以说下详细的流程吗?
答:首先这是一个分类问题,首先应该想到的是可以尝试使用常用的分类算法,例如朴素贝叶斯、决策树或者SVM。拿到数据之后,做的第一件事就是特征工程。然后将数据分类两部分,一部分用于训练,另一部分用于测试,即分为训练集和测试集,不混用。其实,使用什么分类算法倒是其次,重要在于选好特征,对于给定的特征,需要做一些过滤,比如一些干扰数据,如果对于结果影响很大,可以尝试舍弃这些数据。除此之外,看看是否需要对数据进行归一化处理,将数据无量纲化。然后对已经处理好的特征,送入分类算法中,让其学习。最后,可以通过查看测试集的预测准确度,对一些算法必要参数进行优化调试。
解析:我当时差不多就是这么回答的,我感觉只要说的,让面试官认为你做过相关工作即可。
2、如果给你1亿个数据,让你找出其中第1000大的数据,你会怎么做?我们先不考虑多进程和多线程,也不考虑数据库,如何在算法方面给出思路呢?
答:可以使用堆排序,创建一个存储1000个数据的小根堆。先将1亿个数据的前1000个数据放入这个小根堆中,然后继续遍历,对于新插入的数据,需要与小根堆的最小值进行比较,如果待插入的数据比这个最小值还小,那么不插入,如果比这个最小值大,那么就插入该数,并重新调整小根堆,随后继续使用此方法遍历整个数据。遍历一次数据后,就得到了前1000大的数据,然后输出小根堆的最小值,即根值,即可得到第1000大的数据。
解析:这道题当时能想到的就是用堆实现了,其他更好的方法欢迎探讨。
三、总结
- 有的题目已经忘记了,记不清了就暂不记录了,本文会根据后续面试进行持续更新。
- 本文中的一些问题并不一定是标准答案,只是自己的一点小认识;
- 本文中提到的问题并不是一场面试的题目,而是很多公司面试题目的集合;
- 在线编程题出的题目不会太难,本文提到的题目都是现场提问的;
- 自己认真、限时写出编程基础题很重要,要多多练习,自己练习的时候可能没有问题,但是当现场面试的时候,如果不熟悉,往往会很慌,反而写不出来了。
- 如有错误或更好的见解,欢迎指正讨论。
来源:
https://cuijiahua.com/blog/2018/04/life_2.html







