
一直保持的追求有三点:技术、快乐、财富,这里记录每周值得分享的内容,周五把欢乐送达。
技术
1、Taichi
Taichi 是 MIT PhD 胡渊鸣大神为了解决计算机图形学研究对性能的追求以及生产力低下的问题,而设计的全新的编程语言。
Taichi 持续更新了几年之久,为了使工具使用起来更加简化,作者又增加了 Differentiable Programming (可微编程),无需手动求导数,程序可以自动微分。随后,为了方便人们使用,作者再次对工具进行了升级,提供了Python的接口,使其更广范围地传播。
凭借对于 Taichi 的维护和更新,作者也发表了多篇顶级会议文章。良好的性能,简单的接口,使 Taichi 成为了简单好用的计算机图形学工具。
Taichi 的演示功能有很多,包括物质点法、有限元模拟、多重网格泊松方程求解、真实感渲染和3D稀疏卷积神经网络等。
非专业人士对于物质点法、有限元模拟这些,可能没有直观的感受,不知道是什么。没关系,真实感渲染,应该都能理解。
例如,简单的几行代码,就可以写一个简单的连续介质模拟器,模拟两种相互作用的不同材料(水、木水轮),并且在你的笔记本上就能运行:

99行代码就可以进行雪的模拟,模拟三种相互作用的不同材料(水,果冻,雪):
Taichi 对于电影特效、VR、深度学习等多种领域的发展,一定会起到很大的帮助作用。
作者原文:点击查看
项目地址:点击查看
2、基于 OCR 的身份证要素提取
『基于 OCR 的身份证要素提取』是 CCF 大数据与计算智能大赛的一场竞赛。
身份证影像文件包含姓名、地址等多项个人基本信息,信息准确度和权威性高,在商业银行中被广泛应用于身份认证、信息采集等领域。
然而,商业银行的影像数据来源渠道复杂,时间跨度很大,质量层次不齐,目前市面上的身份证识别模型尚不能满足银行质量参差的影像识别需求。因此,一个具备强抗噪声干扰能力的 OCR 模型有着极高的商业价值。
名为『天晨破晓』的团队,获得了这个比赛的冠军,并荣获了”最佳创新探索奖”。
团队采用条件生成对抗网络(CGAN)处理赛题中的水印干扰,并结合OCR检测模块和识别模块,高准确率地提取了多项个人信息,准确率达0.996952。现在,团队开源了获得top1成绩的代码。

对基于 OCR 的身份证要素提取感兴趣的,可以看下。
项目地址:点击查看
3、DeepDanbooru
DeepDanbooru 是一个针对二次元图片的 tag 属性识别算法。
输入一张二次元图片,可以输出图片的多维的属性 tag,例如,鬼灭之刃的炭太郎,可以输出12维特征。

DeepDanbooru 是基于 Tensorflow 框架的,暂未提供 pre-train model,但提供的 web demo,可以在线体验。
基于 DeepDanbooru,也可以试试真人图片的属性 tag 识别。
项目地址:点击查看
4、EfficientDet
EfficientDet 目标检测算法在之前的文章提到过,它是谷歌大脑团队研究的新算法。
EfficientDet 结构简洁只使用了 52M 参数,326B FLOPS 的 EfficientDet-D7 在 COCO 数据集上实现了当前最优的 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,FLOPS 计算量更是降低 9倍 之多。
EfficientDet 还没有官方开源代码,都是民间高手复现。
近日,一个名为 Signatrix 的柏林团队,也对 EfficientDet 进行了复现并开源,效果如下:

很多人都对 EfficientDet 目标检测算法进行了复现,说明这个算法的效果确实很好。感兴趣的,可以看一看。
项目地址:点击查看
5、chinese-poetry
chinese-poetry 是一个号称“最全中文诗歌古典文集数据库”的项目。包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。
从某种意义上来说,这些庞大的文集离我们是有一定距离的。而电子版方便拷贝,所以此开源数据库诞生了。此数据库通过 JSON 格式分发,可以让你很方便的开始你的项目。
目前,仓库中一共有10个数据集,分别是:全唐诗、全宋诗、全宋词、五代·花间集、五代·南唐二主词、论语、诗经、幽梦影、四书五经、蒙学。
基于这个庞大的诗词数据库,可以做些很多有趣的开发,例如可以采用 nlp 技术,训练一个“诗人”,写诗创作,也可以训练一个藏头诗高手。

对于中文诗歌古典文集感兴趣的,赶紧收藏一下吧。
项目地址:点击查看
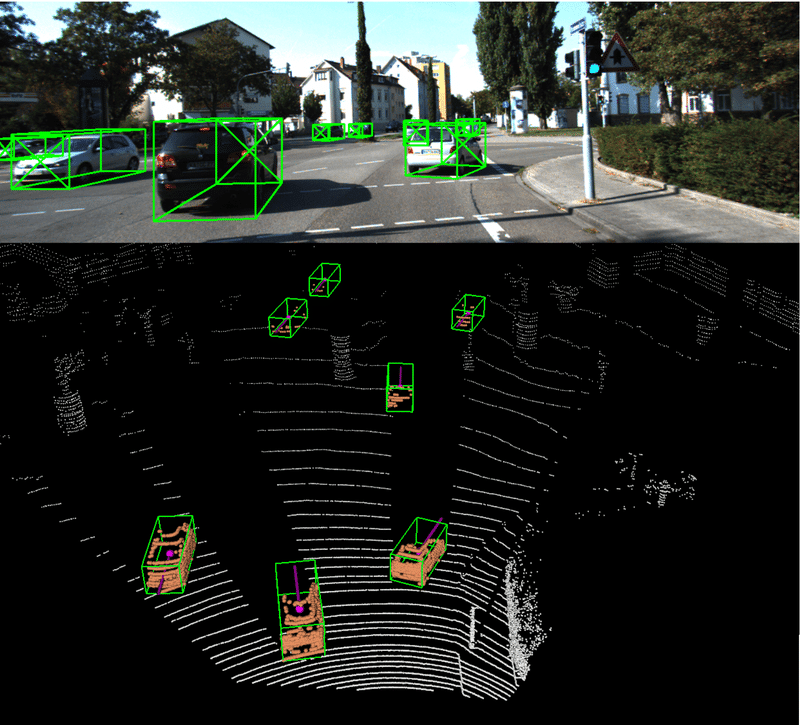
6、Det3D
Det3D 是业界首个开源的通用 3D 目标检测框架。
2D 检测目前是一个非常成熟的领域,各种优秀的框架(Detectron2 / mmDetection, etc)不计其数,研究人员基于某一个框架,可以快速验证想法,而不需要去关心如何适配某种数据集、如何做增强、如何给数据加速等等,大大节省了做 research 的工程成本。
而应用于自动驾驶、室内导航等领域的 3D 检测一直没有一个通用的框架,各种 3D 目标检测算法群魔乱舞,而 Det3D 框架的开源就打破了这个混乱的局面。
Det3D 支持的数据集:KITTI、nuScenes、Lyft。
目前支持的模型:VoxelNet、SECOND、CBGS、Point Pillars、PIXOR、PointNet++、Point RCNN (即将 release)。
项目地址:点击查看
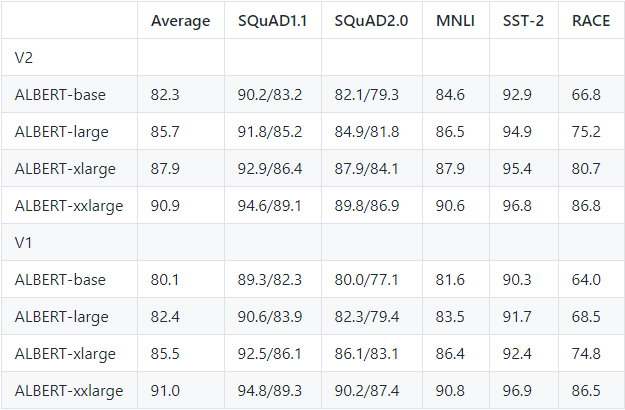
7、ALBERT
ALBERT 是 Google 研究的轻量级 NLP 模型,我曾在《程序员欢乐送(第37期)》中介绍过,写这篇文章的时候,Google 官方还没有开源。
ALBERT 又叫 A LITE BERT,顾名思义就是一个轻量级的 BERT 模型。而 ALBERT 比 BERT 模型参数小18倍,性能还超越了它。
不仅如此,还横扫各大“性能榜”,在 SQuAD 和 RACE 测试上创造了新的 SOTA。最近,谷歌升级了 ALBERT,支持中文并提供了 Version2 版本。
项目地址:点击查看
快乐
1、小宝宝显得有点无辜

虽然我只是 8 个月大的宝宝,但因为涉嫌违反交通规则被监控拍到了。
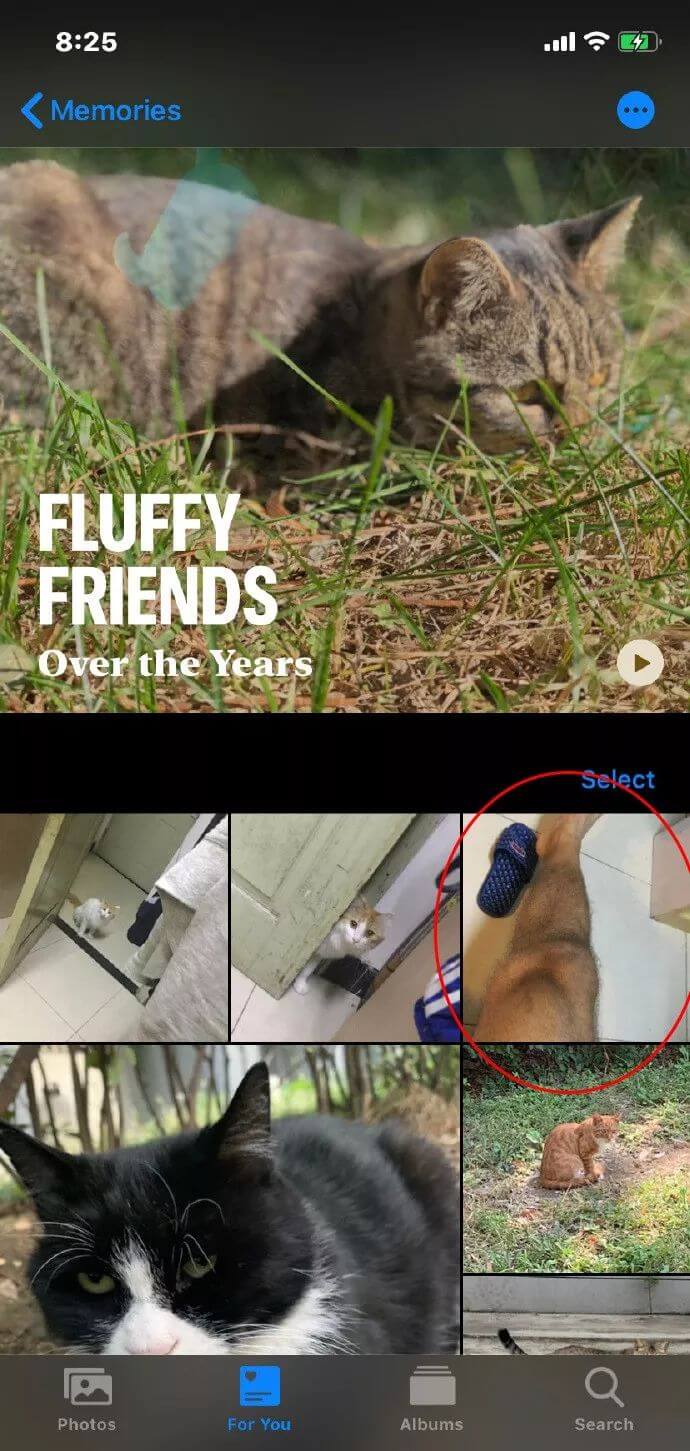
2、相册这个智能分类
财富
上篇推送提到了 IRR,用于计算定期、定额的投资或贷款等产品的真实利率,也就是算那种有规律的投资或者贷款,比如定投、月供什么的。
但是,很多人理财是没有时间规律的,往往是手上有了余钱,就投进去一笔。
这样如何算理财收益?计算不定时、不定额的理财产品的真实利率,可以用 XIRR。
举个真实例子,我定投的 500ETF。
A股近期涨势很好,一路高歌猛进,创业板飙升 20% 以上。我自己定投的 500ETF 大杂烩,也涨了不少,目前盈利 9.2%。如果开盘后,我按照此价格(理想状态),将所有股票卖出,那么我就能赚 9.2%,也就是赚 3200 多元。那么,我的年化收益率怎么算呢?
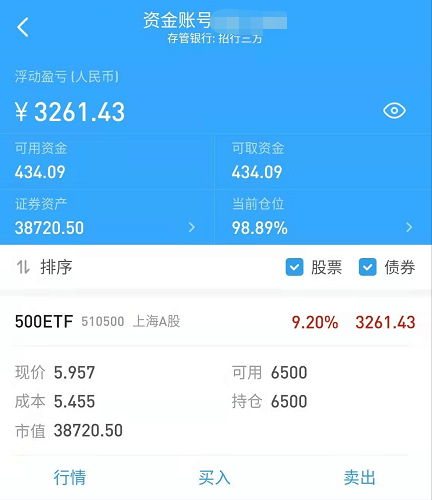
先整理下投资记录:
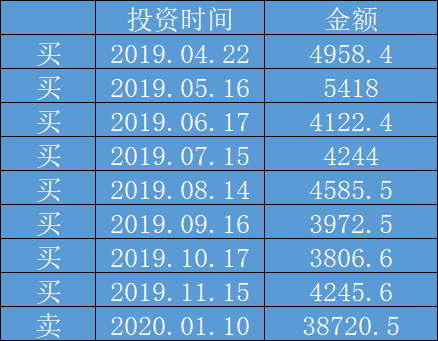
我从4月份,每个月的月中,坚持买4000元左右的 500ETF,当月跌的多,多买点;涨的多了,少买点。12月怂了,没有买。假设2020年1月10日,基金顺利卖出,获得38720.5元。
使用 XIRR 计算真实利率:
import datetime
from scipy import optimize
def xnpv(rate, cashflows):
return sum([cf/(1+rate)**((t-cashflows[0][0]).days/365.0) for (t,cf) in cashflows])
def xirr(cashflows, guess=0.1):
try:
return optimize.newton(lambda r: xnpv(r,cashflows),guess)
except:
print('Calc Wrong')
data = [(datetime.date(2019,4,22), -4958.4), (datetime.date(2019,5,16), -5418), (datetime.date(2019,6,17), -4122.4), (datetime.date(2019,7,15), -4244), (datetime.date(2019,8,14), -4585.5), (datetime.date(2019,9,16), -3972.5), (datetime.date(2019,10,17), -3806.6), (datetime.date(2019,11,15), -4245.6), (datetime.date(2020,1,10), 38720.5)]
xirr_res = xirr(data)
print('年化收益率:%.2f%%' % (xirr_res * 100))
计算结果:
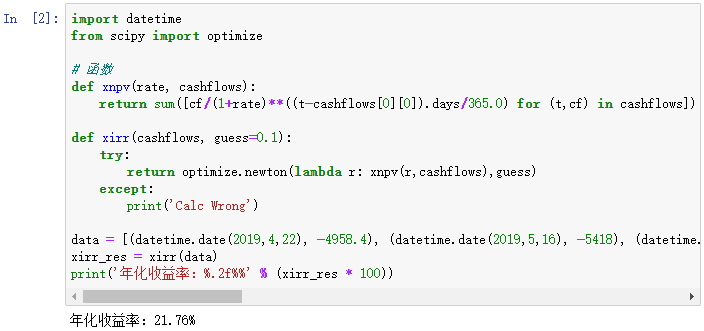
XIRR 算出来的,直接就是年化利率了,不用像 IRR 那样,再多一个公式去折算。
最终,我的年化收益率为 21.76%。
最后,再说下A股。A股涨势不错,没上车的朋友,可以择机上车了。2020年,看这趟车能开多久。
最后
本周的程序员欢乐送,到此结束,下周再会。
来源:
https://cuijiahua.com/blog/2020/01/life-57.html








