推荐系统是一种根据用户的选择来预测或过滤偏好的系统。推荐系统广泛用于电影, 音乐, 新闻, 书籍, 研究文章, 搜索查询, 社交标签和产品等各个领域。
推荐系统以两种方式中的任何一种生成建议列表:
- 协同过滤:协作过滤方法会根据用户的过去行为(即用户购买或搜索的商品)以及其他用户做出的类似决策来构建模型。然后, 此模型用于预测用户可能感兴趣的项目(或项目的评级)。
- 基于内容的过滤:基于内容的过滤方法使用项目的一系列离散特征, 以便推荐具有类似属性的其他项目。基于内容的过滤方法完全基于商品说明和用户偏好设置。它根据用户过去的偏好来推荐商品。
让我们使用Python和Pandas开发一个基本的推荐系统。
让我们专注于提供基本的推荐系统, 方法是建议与某个特定项目(在本例中为电影)最相似的项目。它只是告诉你哪些电影/项目与用户选择的电影最相似。
要下载文件, 请单击链接–.tsv文件, Movie_Id_Titles.csv.
导入带有定界符” \ t”的数据集, 因为该文件是tsv文件(制表符分隔的文件)。
# import pandas library
import pandas as pd
# Get the data
column_names = [ 'user_id' , 'item_id' , 'rating' , 'timestamp' ]
path = 'https://media.srcmini.org/wp-content/uploads/file.tsv'
df = pd.read_csv(path, sep = '\t' , names = column_names)
# Check the head of the data
df.head()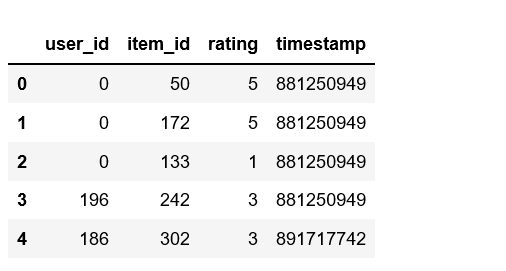
# Check out all the movies and their respective IDs
movie_titles = pd.read_csv( 'https://media.srcmini.org/wp-content/uploads/Movie_Id_Titles.csv' )
movie_titles.head()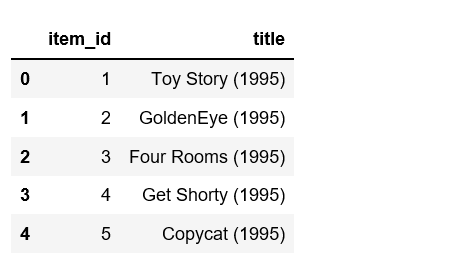
data = pd.merge(df, movie_titles, on = 'item_id' )
data.head()
# Calculate mean rating of all movies
data.groupby( 'title' )[ 'rating' ].mean().sort_values(ascending = False ).head()
# Calculate count rating of all movies
data.groupby( 'title' )[ 'rating' ].count().sort_values(ascending = False ).head()
# creating dataframe with 'rating' count values
ratings = pd.DataFrame(data.groupby( 'title' )[ 'rating' ].mean())
ratings[ 'num of ratings' ] = pd.DataFrame(data.groupby( 'title' )[ 'rating' ].count())
ratings.head()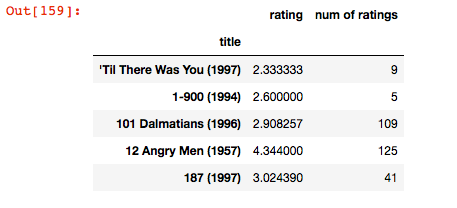
可视化导入:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style( 'white' )
% matplotlib inline# plot graph of 'num of ratings column'
plt.figure(figsize = ( 10 , 4 ))
ratings[ 'num of ratings' ].hist(bins = 70 )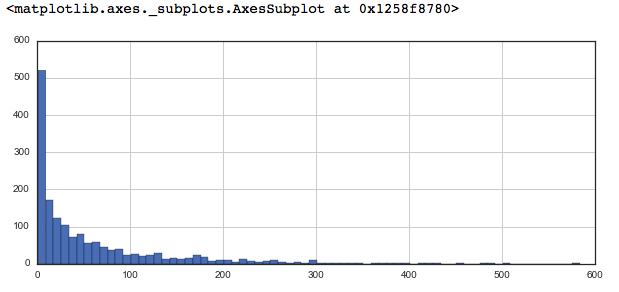
# plot graph of 'ratings' column
plt.figure(figsize = ( 10 , 4 ))
ratings[ 'rating' ].hist(bins = 70 )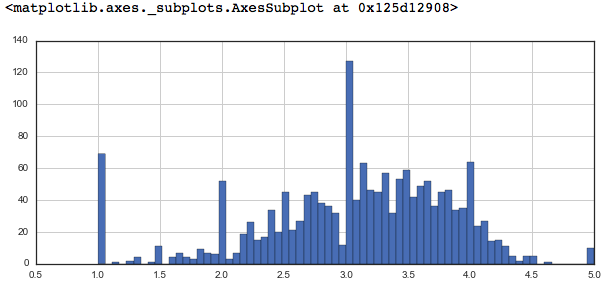
# Sorting values according to
# the 'num of rating column'
moviemat = data.pivot_table(index = 'user_id' , columns = 'title' , values = 'rating' )
moviemat.head()
ratings.sort_values( 'num of ratings' , ascending = False ).head( 10 )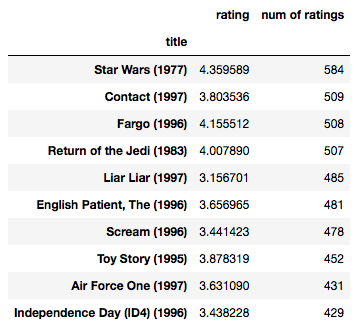
# analysing correlation with similar movies
starwars_user_ratings = moviemat[ 'Star Wars (1977)' ]
liarliar_user_ratings = moviemat[ 'Liar Liar (1997)' ]
starwars_user_ratings.head()
# analysing correlation with similar movies
similar_to_starwars = moviemat.corrwith(starwars_user_ratings)
similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings)
corr_starwars = pd.DataFrame(similar_to_starwars, columns = [ 'Correlation' ])
corr_starwars.dropna(inplace = True )
corr_starwars.head()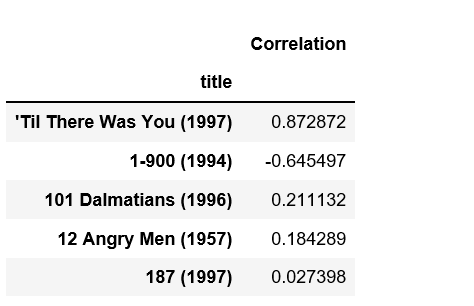
# Similar movies like starwars
corr_starwars.sort_values( 'Correlation' , ascending = False ).head( 10 )
corr_starwars = corr_starwars.join(ratings[ 'num of ratings' ])
corr_starwars.head()
corr_starwars[corr_starwars[ 'num of ratings' ]> 100 ].sort_values( 'Correlation' , ascending = False ).head()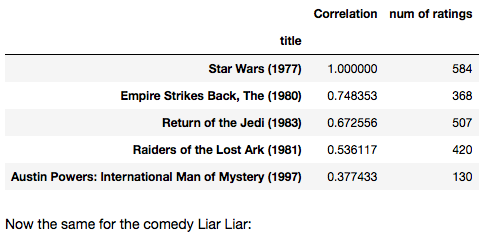
# Similar movies as of liarliar
corr_liarliar = pd.DataFrame(similar_to_liarliar, columns = [ 'Correlation' ])
corr_liarliar.dropna(inplace = True )
corr_liarliar = corr_liarliar.join(ratings[ 'num of ratings' ])
corr_liarliar[corr_liarliar[ 'num of ratings' ]> 100 ].sort_values( 'Correlation' , ascending = False ).head()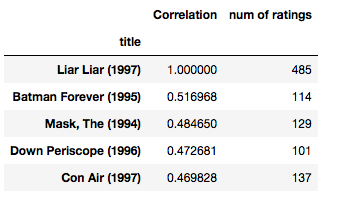
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
来源:
https://www.srcmini02.com/70363.html



