自然语言处理(NLP)是计算机科学和人工智能领域, 与计算机和人类(自然)语言之间的相互作用有关, 尤其是如何对计算机进行编程以处理和分析大量自然语言数据。这是机器学习的一个分支, 它涉及分析任何文本并处理预测分析。
Scikit学习是针对Python编程语言的免费软件机器学习库。 Scikit-learn主要用Python编写, 一些核心算法用Cython编写以实现性能。 Cython是Python编程语言的超集, 旨在通过主要用Python编写的代码来提供类似于C的性能。
让我们了解文本处理和NLP流程所涉及的各个步骤。
该算法可以轻松应用于其他任何类型的文本, 例如将书籍分类为”浪漫”, “摩擦”, 但现在, 让我们使用餐厅评论审查负面或正面反馈的数据集。
涉及的步骤:
第1步:导入数据集并将定界符设置为” \ t”, 因为列被分隔为制表符空间。评论及其类别(0或1)没有用其他任何符号分隔, 但带有制表符空格, 因为大多数其他符号是评论(例如, 价格为$, …。!等), 算法可能会将它们用作分隔符, 这会在输出中导致奇怪的行为(例如错误, 奇怪的输出)。
# Importing Libraries
import numpy as np
import pandas as pd
# Import dataset
dataset = pd.read_csv( 'Restaurant_Reviews.tsv' , delimiter = '\t' )要下载使用的Restaurant_Reviews.tsv数据集, 请单击这里.
第2步:文字清理或预处理
删除标点符号:在给定的文本中, 标点符号没有太大的帮助, 如果包含的话, 它们只会增加我们将在最后一步中创建的词袋的大小, 并降低算法的效率。
抽干:扎根词
将每个单词都转换成小写:例如, 在不同情况下使用相同的单词(例如”好”和”好”)是没有用的。
# library to clean data
import re
# Natural Language Tool Kit
import nltk
nltk.download( 'stopwords' )
# to remove stopword
from nltk.corpus import stopwords
# for Stemming propose
from nltk.stem.porter import PorterStemmer
# Initialize empty array
# to append clean text
corpus = []
# 1000 (reviews) rows to clean
for i in range ( 0 , 1000 ):
# column : "Review", row ith
review = re.sub( '[^a-zA-Z]' , ' ' , dataset[ 'Review' ][i])
# convert all cases to lower cases
review = review.lower()
# split to array(default delimiter is " ")
review = review.split()
# creating PorterStemmer object to
# take main stem of each word
ps = PorterStemmer()
# loop for stemming each word
# in string array at ith row
review = [ps.stem(word) for word in review
if not word in set (stopwords.words( 'english' ))]
# rejoin all string array elements
# to create back into a string
review = ' ' .join(review)
# append each string to create
# array of clean text
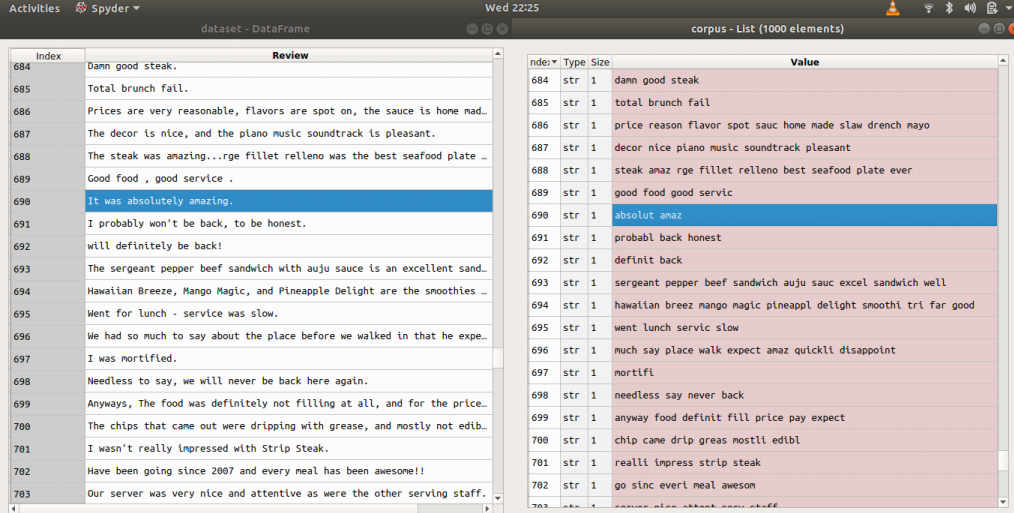
corpus.append(review)例子:在应用上述代码之前和之后(评论=>之前, 语料库=>之后)
第三步: 代币化, 涉及从正文中拆分句子和单词。
步骤4:通过稀疏矩阵制作单词袋
- 取数据集中评论的所有不同单词, 而无需重复单词。
- 每个单词一列, 因此会有很多列。
- 行是评论
- 如果评论数据集中的行中有单词, 则单词计数将在单词列下的单词袋行中存在。
例子:让我们收集只有两个评论的评论数据集
Input : "dam good steak", "good food good servic"
Output :为此, 我们需要CountVectorizer类,来自sklearn.feature_extraction.text。
我们还可以设置最大数量的功能(通过属性” max_features”提供最大帮助的最大数量的功能)。对语料库进行训练, 然后对语料库” .fit_transform(corpus)”应用相同的转换, 然后将其转换为数组。如果评论是肯定的还是否定的, 那么答案在dataset [:, 1]的第二列中:所有行和第一列(从零开始索引)。
# Creating the Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
# To extract max 1500 feature.
# "max_features" is attribute to
# experiment with to get better results
cv = CountVectorizer(max_features = 1500 )
# X contains corpus (dependent variable)
X = cv.fit_transform(corpus).toarray()
# y contains answers if review
# is positive or negative
y = dataset.iloc[:, 1 ].values要使用的数据集的描述:用\ t分隔的列(制表符空间)第一列是关于人的评论的第二列中, 0代表负面评论, 1代表正面评论

步骤5:
将语料库分为训练和测试集。为此, 我们需要sklearn.cross_validation中的class train_test_split。可以拆分为70/30或80/20或85/15或75/25, 这里我通过” test_size”选择75/25。
X是单词袋, y是0或1(正数或负数)。
# Splitting the dataset into
# the Training set and Test set
from sklearn.cross_validation import train_test_split
# experiment with "test_size"
# to get better results
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25 )步骤6:拟合预测模型(此处为随机森林)
- 由于Random fored是sklearn.ensemble的集成模型(由许多树组成), 因此请导入RandomForestClassifier类
- 具有501树或” n_estimators”, 且标准为”熵”
- 通过.fit()方法使用属性X_train和y_train拟合模型
# Fitting Random Forest Classification
# to the Training set
from sklearn.ensemble import RandomForestClassifier
# n_estimators can be said as number of
# trees, experiment with n_estimators
# to get better results
model = RandomForestClassifier(n_estimators = 501 , criterion = 'entropy' )
model.fit(X_train, y_train)步骤7:通过使用带有属性X_test的.predict()方法对最终结果进行定价
# Predicting the Test set results
y_pred = model.predict(X_test)
y_pred
注意:随机森林的准确度为72%(在使用不同测试大小进行的实验中可能会有所不同, 此处= 0.25)。
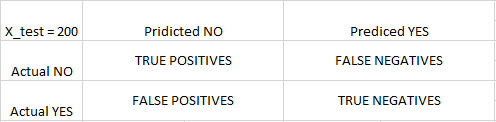
步骤8:为了知道准确性, 需要混淆矩阵。
混淆矩阵是2X2矩阵。
TRUE POSITIVE:测量正确识别的实际阳性的比例。 TRUE NEGATIVE:测量未正确识别的实际阳性的比例。假阳性:衡量正确识别的实际阴性的比例。假阴性:测量未正确识别的实际阴性的比例。
注意 :
正确或错误表示分配的类别是正确还是不正确, 而肯定或否定的是指分配给肯定或否定类别
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cm
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。
来源:
https://www.srcmini02.com/69854.html



