
下面列出了最常问到的数据结构面试问题和答案。
1)什么是数据结构?说明。
数据结构是一种指定如何组织和操作数据的方式。它还定义了它们之间的关系。数据结构的一些示例是数组, 链接列表, 堆栈, 队列等。数据结构是许多计算机科学算法的核心部分, 因为它们使程序员能够高效地处理数据。
2)描述数据结构的类型?
数据结构主要分为两种类型:
线性数据结构:如果数据结构的所有元素都按顺序排列, 则称其为线性。在线性数据结构中, 元素以非分层方式存储, 其中每个项目都具有除第一个和最后一个元素以外的后继者和前任者。
非线性数据结构:非线性数据结构不会形成序列, 即每个项目或元素都以非线性排列方式与两个或多个其他项目连接。数据元素未按顺序结构排列。
3)列出数据结构的应用领域。
数据结构广泛应用于以下计算机科学领域:
- 编译器设计
- 操作系统,
- 数据库管理系统,
- 统计分析包
- 数值分析,
- 图形,
- 人工智能,
- 模拟
4)文件结构和存储结构有什么区别?
文件结构和存储结构之间的区别:
文件结构和存储结构之间的主要区别是基于要访问的内存区域。
存储结构:它是计算机内存中数据结构的表示。
文件结构:它是辅助存储器中存储结构的表示。
5)列出在RDBMS, 网络数据模态和分层数据模型中使用的数据结构。
- RDBMS使用数组数据结构
- 网络数据模型使用图
- 层次数据模型使用树
6)哪种数据结构用于执行递归?
堆栈数据结构由于具有后进先出的特性, 因此在递归中使用。操作系统维护堆栈, 以便在每次函数调用时保存迭代变量
7)什么是堆栈?
堆栈是一个有序列表, 其中只能在称为顶端的一端执行插入和删除操作。它是一种递归数据结构, 具有指向其顶部元素的指针。堆栈有时被称为后进先出(LIFO)列表, 即首先从堆栈中插入的元素将从堆栈中最后删除。
8)列出可以使用堆栈数据结构的应用程序区域?
- 表达评估
- 回溯
- 内存管理
- 函数调用和返回
9)堆栈上可以执行哪些操作?
- 推送操作
- 流行乐
- 窥视操作
10)写入堆栈溢出条件。
当top = Maxsize -1时发生溢出
11)PUSH和POP有什么区别?
PUSH和POP操作指定如何在堆栈中存储和检索数据。
PUSH:PUSH指定将数据”插入”到堆栈中。
POP:POP指定数据检索。这意味着正在从堆栈中删除数据。
12)编写涉及在堆栈中插入和删除元素的步骤。
推:
- 递增变量top, 以便它可以引用下一个内存分配
- 将项目复制到与顶部索引值相等的数组
- 重复步骤1和2, 直到堆栈溢出
流行:
- 将最上面的元素存储到另一个变量中
- 降低顶端的价值
- 返回最上面的元素
13)什么是后缀表达式?
运算符跟随操作数的表达式称为后缀表达式。这种形式的主要好处是, 无需将括号中的子表达式分组或考虑运算符的优先级。
表达式” a + b”将以后缀表示法表示为” ab +”。
14)写出表达式的后缀形式:(A + B)*(C-D)
AB + CD- *
)15)在使用前缀和后缀形式的算术表达式的求值中使用哪些符号?
波兰语和反向波兰语符号。
16)什么是数组?
数组定义为存储在连续内存位置的相似类型数据项的集合。它是最简单的数据结构, 其中每个数据元素都可以使用其索引号进行随机访问。
17)如何引用一维数组中的所有元素?
可以通过使用索引循环来完成此工作, 以使计数器从0到数组大小减一。通过这种方式, 你可以将循环计数器用作数组下标, 从而依次引用所有元素。
18)什么是多维数组?
多维数组可以定义为其中数组以行和列组成的表格形式存储的数组的数组。创建2D数组以实现类似关系数据库的数据结构。它使一次性保存大量数据变得容易, 可以在需要时将其传递给任意数量的函数。
19)二维数组的元素如何存储在存储器中?
使用两种技术可以将2D数组的元素存储在内存中。
- 行优先顺序:按行优先顺序, 二维数组的所有行都连续存储到内存中。首先, 将数组的第一行完全存储到内存中, 然后将数组的第二行完全存储到内存中, 依此类推, 直到最后一行。
- 列优先顺序:按列优先顺序, 将2D数组的所有列连续存储到内存中。首先, 将数组的第一列完全存储到内存中, 然后将数组的第二行完全存储到内存中, 依此类推, 直到数组的最后一列。
20)计算2D数组中存在的随机元素的地址, 给定基本地址为BA。
行优先顺序:如果将数组声明为a [m] [n], 其中m是行数, 而n是列数, 则存储在row中的数组元素a [i] [j]的地址大订单计算为
地址(a [i] [j])= B. A. +(i * n + j)*大小
列大顺序:如果将数组声明为a [m] [n], 其中m是行数, 而n是列数, 则存储在column中的数组元素a [i] [j]的地址大订单计算为
地址(a [i] [j])=((j * m)+ i)*大小+ BA。
21)定义链表数据结构。
链接列表是称为节点的随机存储数据对象的集合。在”链接列表”中, 每个节点都通过指针链接到其相邻节点。节点包含两个字段, 即数据字段和链接字段。

22)链表是否被视为线性或非线性数据结构?
根据情况, 链表被视为线性和非线性数据结构。
- 在数据存储的基础上, 它被视为非线性数据结构。
- 在访问策略的基础上, 它被视为线性数据结构。
23)与数组相比, 链表的优点是什么?
- 链表的大小可以在运行时增加, 对于数组, 这是不可能的。
- 该列表不需要连续存在于主内存中, 如果连续空间不可用, 则可以将节点存储在通过链接连接的内存中的任何位置。
- 该列表动态存储在主存储器中, 并根据程序需求增长, 而数组静态存储在主存储器中, 其大小必须在编译时声明。
- 链表中的元素数量仅限于可用的存储空间, 而数组中的元素数量仅限于数组的大小。
24)用C编写语法, 以在单链表中创建一个节点。
struct node
{
int data;
struct node *next;
};
struct node *head, *ptr;
ptr = (struct node *)malloc(sizeof(struct node));25)如果你正在使用C语言实现异构链表, 则应使用哪种指针类型?
异构链表包含不同的数据类型, 因此无法为此使用普通指针。为此, 你必须使用诸如void指针之类的通用指针类型, 因为void指针能够存储指向任何类型的指针。
26)什么是双向链表?
双链表是链表的一种复杂类型, 其中节点包含指向序列中上一个节点和下一个节点的指针。在双向链表中, 节点由三部分组成:
- 节点数据
- 指向顺序中下一个节点的指针(下一个指针)
- 指向上一个节点的指针(上一个指针)。
27)编写C程序以在循环开头的单个列表中插入一个节点。
#include<stdio.h>
#include<stdlib.h>
void beg_insert(int);
struct node
{
int data;
struct node *next;
};
struct node *head;
void main ()
{
int choice, item;
do
{
printf("\nEnter the item which you want to insert?\n");
scanf("%d", &item);
beg_insert(item);
printf("\nPress 0 to insert more ?\n");
scanf("%d", &choice);
}while(choice == 0);
}
void beg_insert(int item)
{
struct node *ptr = (struct node *)malloc(sizeof(struct node));
struct node *temp;
if(ptr == NULL)
{
printf("\nOVERFLOW");
}
else
{
ptr -> data = item;
if(head == NULL)
{
head = ptr;
ptr -> next = head;
}
else
{
temp = head;
while(temp->next != head)
temp = temp->next;
ptr->next = head;
temp -> next = ptr;
head = ptr;
}
printf("\nNode Inserted\n");
}
}28)定义队列数据结构。
队列可以定义为一个有序列表, 它使插入操作可以在称为REAR的一端执行, 而删除操作可以在称为FRONT的另一端执行。
29)列出队列数据结构的一些应用。
队列的应用程序如下:
- 队列广泛用作单个共享资源(如打印机, 磁盘, CPU)的等待列表。
- 队列用于数据的异步传输(例如, 两个进程之间的数据传输速率不同)。管道, 文件IO, 套接字。
- 队列在大多数应用程序(例如MP3媒体播放器, CD播放器等)中用作缓冲区。
- 队列用于维护媒体播放器中的播放列表, 以在播放列表中添加和删除歌曲。
- 队列在操作系统中用于处理中断。
30)队列的数组实现有哪些缺点?
- 内存浪费:用于存储队列元素的数组空间不能再用于存储该队列的元素, 因为这些元素只能插入前端, 并且front的值可能很高, 因此, 之前的所有空间都无法填补。
- 数组大小:在某些情况下, 如果我们使用数组实现队列, 则可能需要扩展队列以插入更多元素。几乎不可能扩展数组大小, 因此确定正确的数组大小始终是队列数组实现中的问题。
31)在什么情况下可以将元素插入循环队列?
- 如果(rear + 1)%maxsize = front, 则队列已满。在这种情况下, 会发生溢出, 因此无法在队列中执行插入。
- 如果后方!= max-1, 则后方将增加到mod(maxsize), 并且新值将插入队列的后端。
- 如果front!= 0且Rear = max-1, 则表示队列未满, 因此, 将Rear的值设置为0并在其中插入新元素。
32)什么是出队?
出队(也称为双端队列)可以定义为元素的有序集合, 其中可以在两端(即前后)执行插入和删除操作。
33)可用于实现优先级队列的最小队列数是多少?
需要两个队列。一个队列用于存储数据元素, 另一个用于存储优先级。
34)定义树数据结构。
树是一种递归数据结构, 包含一个或多个数据节点的集合, 其中一个节点被指定为树的根, 而其余节点被称为根的子节点。除根节点以外的其他节点均被划分为多个非空集, 其中每个空集都称为子树。
35)列出树的类型。
共有以下六种树。
- 普通树
- 森林
- 二叉树
- 二分搜索树
- 表达树
- 比赛树
36)什么是二叉树?
二叉树是泛型树的一种特殊类型, 其中每个节点最多可以有两个孩子。二叉树通常被分为三个不相交的子集, 即节点的根, 左子树和右二叉子树。
37)编写C代码以在二叉树上执行有序遍历。
void in-order(struct treenode *tree)
{
if(tree != NULL)
{
in-order(tree→ left);
printf("%d", tree→ root);
in-order(tree→ right);
}
}38)高度为k的二叉树中最大节点数是多少?
2k + 1-1, 其中k> = 1
39)哪种数据结构最适合树结构?
队列数据结构
40)哪种数据结构最适合树结构?
队列数据结构
41)编写递归C函数以计算二叉树中存在的节点数。
int count (struct node* t)
{
if(t)
{
int l, r;
l = count(t->left);
r=count(t->right);
return (1+l+r);
}
else
{
return 0;
}
}42)编写一个递归C函数以计算二叉树的高度。
int countHeight(struct node* t)
{
int l, r;
if(!t)
return 0;
if((!(t->left)) && (!(t->right)))
return 0;
l=countHeight(t->left);
r=countHeight(t->right);
return (1+((l>r)?l:r));
}43)与二分搜索树相比, AVL树在所有操作中如何有用?
AVL树通过不使其偏斜来控制二分搜索树的高度。在高度为h的二叉搜索树中, 所有操作所需的时间为O(h)。但是, 如果BST偏斜(即最坏的情况), 则可以将其扩展为O(n)。通过将此高度限制为log n, AVL树将每个操作的上限设置为O(log n), 其中n是节点数。
44)陈述B树的属性。
顺序为m的B树包含M方法树的所有属性。此外, 它包含以下属性。
- B树中的每个节点最多包含m个子节点。
- 除了根节点和叶节点之外, B树中的每个节点至少包含m / 2个子节点。
- 根节点必须至少具有2个节点。
- 所有叶节点必须处于同一级别。
45)B树和B +树有什么区别?
| SN | B Tree | B +树 |
|---|---|---|
| 搜索键不能重复存储。 | 可能存在冗余搜索键。 | |
| 数据可以存储在叶节点以及内部节点中 | 数据只能存储在叶节点上。 | |
| 由于可以在内部节点以及叶节点上找到数据, 因此搜索某些数据的过程较慢。 | 由于只能在叶节点上找到数据, 因此搜索相对较快。 | |
| 内部节点的删除是如此复杂且耗时。 | 删除绝不会是一个复杂的过程, 因为元素将始终从叶节点中删除。 | |
| 叶节点不能链接在一起。 | 叶子节点链接在一起, 使搜索操作更高效。 |
46)列出树形数据结构的一些应用?
树数据结构的应用:
- 算术表达的操纵,
- 符号表构造,
- 语法分析
- 层次数据模型
47)定义图形数据结构?
可以将图G定义为有序集合G(V, E), 其中V(G)表示顶点集合, E(G)表示用于连接这些顶点的边集合。图可以看作是循环树, 其中顶点(节点)在它们之间保持任何复杂的关系, 而不是具有父子关系。
48)区分周期, 路径和电路吗?
- 路径:”路径”是由边连接而没有限制的相邻顶点的序列。
- 循环:循环可以定义为初始顶点与结束顶点相同的闭合路径。路径中的任何顶点均不能访问两次
- 电路:电路可以定义为初始顶点与最终顶点相同的闭合路径。任何顶点都可以重复。
49)提及在图形实现中使用的数据结构。
对于图形实现, 使用以下数据结构。
- 在顺序表示中, 使用邻接矩阵。
- 在链接表示中, 使用邻接列表。
50)BFS和DFS算法中使用哪些数据结构?
- 在BFS算法中, 使用队列数据结构。
- 在DFS算法中, 使用堆栈数据结构。
51)Graph数据结构有哪些应用?
该图具有以下应用程序:
- 图形用在电路网络中, 其中的连接点随着顶点而绘制, 而组成线成为图形的边缘。
- 图形用于运输网络, 在该网络中, 站点被绘制为顶点, 并且路线成为图形的边缘。
- 在地图中使用图形, 将城市/州/地区绘制为顶点, 将邻接关系绘制为边。
- 图形用于程序流分析, 其中过程或模块被视为顶点, 对这些过程的调用被绘制为图形的边缘。
54)在什么情况下, 可以使用二分搜索?
二分搜索算法用于搜索已经排序的列表。该算法遵循分而治之的方法
例:
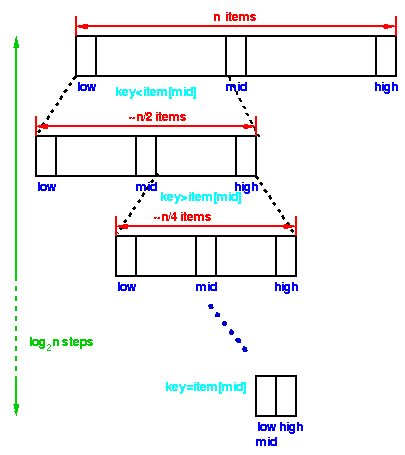
52)与线性搜索相比, 二分搜索有哪些优势?
与线性搜索相比, 二分搜索的比较数量相对较少。通常, 线性搜索需要O(n)时间来搜索n个元素的列表, 而二分搜索需要O(log n)时间来搜索n个元素的列表。
53)选择排序有什么优势?
- 它简单易实现。
- 它可以用于小型数据集。
- 它比气泡排序效率高60%。
55)列出多链接结构的一些应用?
- 稀疏矩阵
- 索引生成。
56)NULL和VOID有什么区别?
- Null实际上是一个值, 而Void是数据类型标识符。
- 空变量仅表示空值, 而void用于将指针标识为没有初始大小。
| Java OOP面试问题 |
| Java字符串和异常问题 |
| JDBC面试问题 |
| JSP面试问题 |
| 休眠面试问题 |
| SQL面试题 |
| Android面试题 |
| MySQL面试问题 |
1
2
3
4
5
Java基础面试问题
Java多线程问题
Java Collection面试题
Servlet面试问题
春季面试问题
PL / SQL面试问题
Oracle面试问题
SQL Server面试问题
来源:
https://www.srcmini02.com/32831.html




