本文概述
本月初, 我做了一个Facebook Live Code With Session, 在其中, 我(以及每个进行编码的人)构建了几种算法, 这些算法的复杂性不断提高, 它们根据给定的数据(例如票价)来预测泰坦尼克号上任何给定的乘客是否幸免于难。有偿, 他们出发的地点和年龄。
在本文中, 你将介绍本节中我们讨论的一些内容。如果你想重新观看或跟随此帖子以及视频, 可以在这里观看:
特别是, 你可能还记得我们建立了监督学习模型。
监督学习是机器学习(ML)的一个分支, 它涉及预测标签, 例如”生存”或”未”。这样的模型从标记的数据中学习, 标记的数据是包括乘客是否幸存的数据(称为”模型训练”), 然后根据未标记的数据进行预测。
在Kaggle(预测性建模和分析竞赛的平台)上, 这些被称为训练和测试集, 因为
- 你想要建立一个模型来学习训练集中的模式, 并且
- 然后, 你可以使用模型对测试集进行预测。
然后Kaggle告诉你你正确的百分比:这就是你模型的准确性。
如何从监督学习开始
你可能已经知道, 进行监督学习的一种好方法是:
- 对数据集执行探索性数据分析(EDA);
- 建立一个快速而肮脏的模型或基线模型, 可以与你将要建立的以后的模型进行比较;
- 重复此过程。你将进行更多的EDA并建立另一个模型;
- 工程师功能:利用你已经拥有的功能并将其组合或从中提取更多信息, 最终达到最后一点
- 获得性能更好的模型。
在会话中的这段代码中, 你已经或将完成所有这些步骤!
请注意, 我们还开设了一些课程, 帮助你开始使用Python和R中的Titanic数据集进行机器学习。
导入数据并签出
第一步始终是导入数据, 以快速签出将要使用的数据。在这种情况下, 你将导入pandas包, 并利用read_csv()函数读取数据:
请注意, 在下面的代码块中, 已经导入了其他软件包和软件包模块, 如matplotlib, sklearn和seaborn。稍后, 你将在(统计)数据可视化和机器学习目的中更广泛地使用它们!
你还可以内联使用IPython魔术命令%matplotlib, 以使绘图在笔记本中内联显示。你还可以将sns.set()添加到代码块中, 以将可视化样式更改为基本的Seaborn样式:
# Import modules
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import tree
from sklearn.metrics import accuracy_score
# Figures inline and set visualization style
%matplotlib inline
sns.set()
事不宜迟, 让我们导入数据并已开始检查数据的第一步:
# Import test and train datasets
df_train = pd.read_csv('../data/train.csv')
df_test = pd.read_csv('../data/test.csv')
# View first lines of training data
df_train.head(n=4)
| 旅客编号 | 幸存下来 | P类 | 名称 | 性别 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 布朗德, 欧文·哈里斯先生 | 男 | 22.0 | 1 | 0 | A / 5 21171 | 7.2500 | NaN | 小号 |
| 1 | 2 | 1 | 1 | 卡明斯, 约翰·布拉德利夫人(佛罗伦萨·布里格斯 | 女 | 38.0 | 1 | 0 | 电脑17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | 海基宁小姐贷款 | 女 | 26.0 | 0 | 0 | STON / O2。 3101282 | 7.9250 | NaN | 小号 |
| 3 | 4 | 1 | 1 | Futrelle, Jacques Heath夫人(莉莉·梅·皮尔) | 女 | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 小号 |
如果你想查看所有这些功能, 请在此处查看Kaggle数据文档。
在继续之前, 最好考虑以下术语:
- 目标变量是你要预测的变量;
- 其他变量称为”功能”(或”预测变量”, 即用于预测目标变量的功能)。
考虑到这一点, 你可以继续使用例如head()函数检出数据, 该函数可用于提取数据集的前五行:
# View first lines of test data
df_test.head()
| 旅客编号 | P类 | 名称 | 性别 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 凯利·詹姆斯先生 | 男 | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | q |
| 1 | 893 | 3 | 威尔克斯, 詹姆斯夫人(艾伦·尼德斯) | 女 | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | 小号 |
| 2 | 894 | 2 | 迈尔斯, 托马斯·弗朗西斯先生 | 男 | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | q |
| 3 | 895 | 3 | 维尔茨, 阿尔伯特先生 | 男 | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | 小号 |
| 4 | 896 | 3 | 赫沃宁, 亚历山大夫人(Helga E Lindqvist) | 女 | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | 小号 |
请注意, df_test DataFrame没有” Survived”列, 因为这是你将要预测的结果!
- 你还可以使用DataFrame .info()方法签出数据类型, 缺少的值以及更多(df_train的)。
df_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
在这种情况下, 你看到具有891行的DataFrame中的”年龄”列只有714个非空值。这意味着有177个空值或缺失值。
- 另外, 请使用DataFrame .describe()方法签出(df_train)数字列的摘要统计信息。
df_train.describe()
| 旅客编号 | 幸存下来 | P类 | 年龄 | 锡卜 | 版本号 | 做 | |
|---|---|---|---|---|---|---|---|
| 计数 | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| 意思 | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| 小时 | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| 我 | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| 最大值 | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
可视探索性数据分析(EDA)和你的第一个模型
现在你已经了解了数据的样子并检查了一些统计数据, 现在该借助seaborn软件包来可视化数据了:
- 例如, 使用seaborn构建泰坦尼克号生存的条形图, 这是你的目标变量。
sns.countplot(x='Survived', data=df_train);

要点:在培训中, 幸存的人少于没有幸存的人。然后, 让我们建立第一个模型, 该模型可以预测没有人幸存。
你知道人们幸存下来, 这是一个糟糕的模型。但这为我们提供了一个基准:我们以后建立的任何模型都需要做得更好。
你可以按照以下步骤进行操作:
- 为df_test创建一列”生存”, 为所有行编码”不生存”;
- 将df_test的’PassengerId’和’Survived’列保存到.csv并提交给Kaggle。
df_test['Survived'] = 0
df_test[['PassengerId', 'Survived']].to_csv('data/predictions/no_survivors.csv', index=False)
这给你带来了什么精度? Kaggle的准确度是62.7。
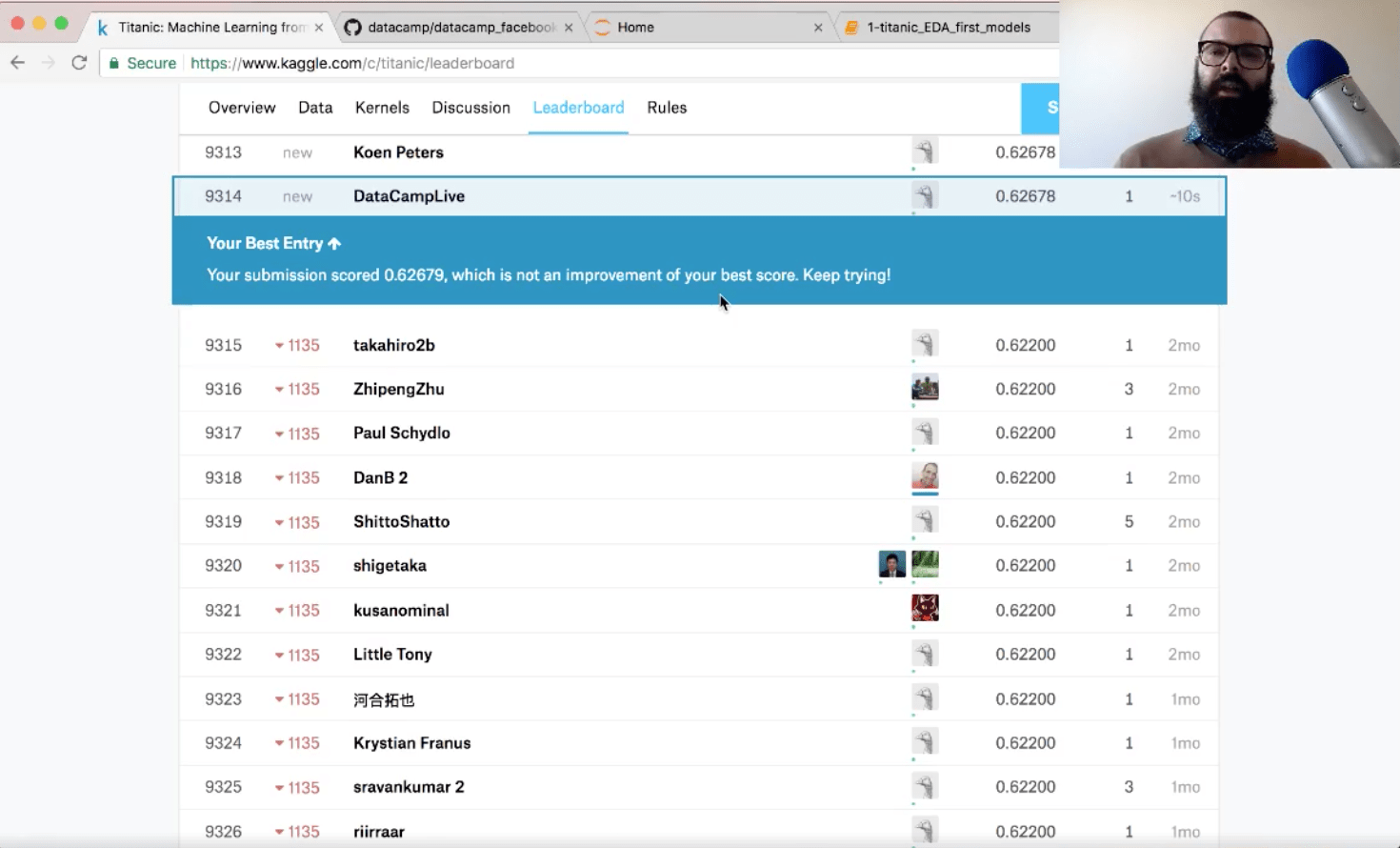
还不错!
重要说明!你还将希望使用准确性以外的指标!
有关特征变量的EDA
现在, 你已经建立了一个快速而又肮脏的模型, 现在该重申一下:让我们做更多的探索性数据分析并尽快建立另一个模型!
- 你可以使用seaborn构建Titanic数据集功能”性”(df_train的)的条形图。
sns.countplot(x='Sex', data=df_train);

- 此外, 还可以使用seaborn在特征”性别”上构建”泰坦尼克号”数据集特征”生存”分割(多面)的条形图。
sns.factorplot(x='Survived', col='Sex', kind='count', data=df_train);

要点:女人比男人更有可能生存。
- 通过此小菜一碟, 你可以使用熊猫来算出有多少女性和多少男性得以幸存:
df_train.groupby(['Sex']).Survived.sum()
Sex
female 233
male 109
Name: Survived, dtype: int64
- 用熊猫算出存活下来的女性比例和男性比例:
print(df_train[df_train.Sex == 'female'].Survived.sum()/df_train[df_train.Sex == 'female'].Survived.count())
print(df_train[df_train.Sex == 'male'].Survived.sum()/df_train[df_train.Sex == 'male'].Survived.count())
0.742038216561
0.188908145581
74%的女性得以幸存, 而19%的男性得以幸存。
现在让我们建立第二个模型, 并预测所有女性都可以幸存下来, 而所有男性都没有。再一次, 这是一个不切实际的模型, 但是它将提供一个基准以与将来的模型进行比较。
- 为df_test创建一列” Survived”, 以对上述预测进行编码。
- 将df_test的’PassengerId’和’Survived’列保存到.csv并提交给Kaggle。
df_test['Survived'] = df_test.Sex == 'female'
df_test['Survived'] = df_test.Survived.apply(lambda x: int(x))
df_test.head()
| 旅客编号 | P类 | 名称 | 性别 | 年龄 | 锡卜 | 版本号 | 票 | 做 | 舱 | 出发 | 幸存下来 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 凯利·詹姆斯先生 | 男 | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | q | 0 |
| 1 | 893 | 3 | 威尔克斯, 詹姆斯夫人(艾伦·尼德斯) | 女 | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | 小号 | 1 |
| 2 | 894 | 2 | 迈尔斯, 托马斯·弗朗西斯先生 | 男 | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | q | 0 |
| 3 | 895 | 3 | 维尔茨, 阿尔伯特先生 | 男 | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | 小号 | 0 |
| 4 | 896 | 3 | 赫沃宁, 亚历山大夫人(Helga E Lindqvist) | 女 | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | 小号 | 1 |
df_test[['PassengerId', 'Survived']].to_csv('../data/predictions/women_survive.csv', index=False)
现在, 当你将模型提交给Kaggle时, 该模型为你提供了什么精度?
Kaggle的准确度是76.6%:
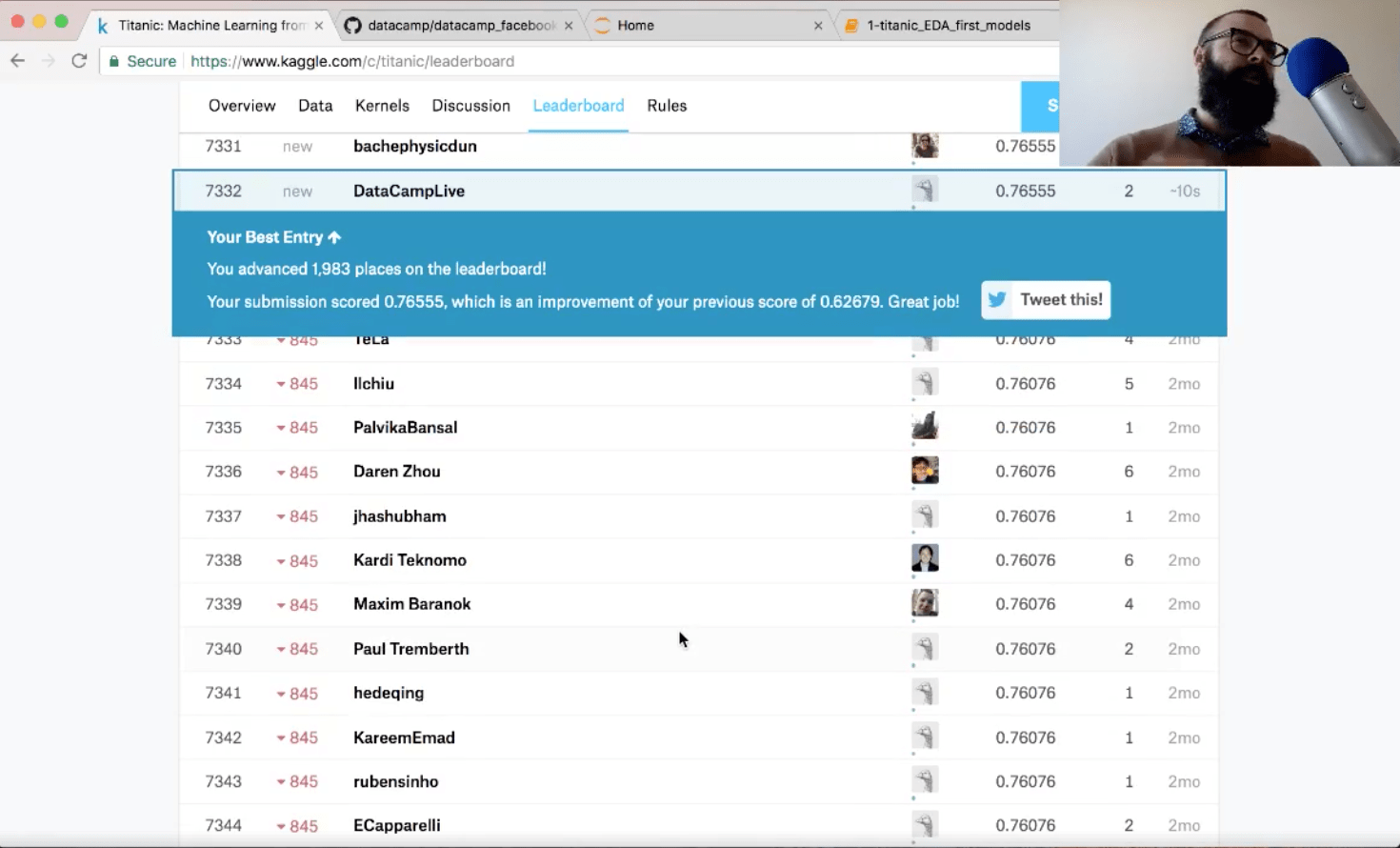
通过此提交, 你在排行榜中上升了约2, 000个位置!此外, 你还提高了分数, 因此做得很好!
进一步探索你的数据!
- 使用seaborn在特征” Pclass”上构建”泰坦尼克号”数据集特征” Survived”的条形图(刻面)。
sns.factorplot(x='Survived', col='Pclass', kind='count', data=df_train);

要点:头等舱旅行的乘客更有可能幸存。另一方面, 乘坐三等舱的旅客很难幸免。
- 使用seaborn来构建泰坦尼克号数据集特征”生存”的条形图(在特征上”分割”(刻面))。
sns.factorplot(x='Survived', col='Embarked', kind='count', data=df_train);

要点:登上南安普敦的乘客存活的可能性较小。
具有数字变量的EDA
- 使用seaborn绘制df_train的”票价”列的直方图。
sns.distplot(df_train.Fare, kde=False);

外卖:大多数乘客乘坐泰坦尼克号旅行的费用不到100美元。
- 使用熊猫绘图方法在同一绘图上为”生存”的每个值绘制”票价”列。
df_train.groupby('Survived').Fare.hist(alpha=0.6);

要点:似乎那些付更多钱的人生存的机会更高。
- 使用seaborn绘制df_train的”年龄”列的直方图。你需要先删除空值。
df_train_drop = df_train.dropna()
sns.distplot(df_train_drop.Age, kde=False);

- 在x轴上绘制带”幸存者”的地带图和群体图。
sns.stripplot(x='Survived', y='Fare', data=df_train, alpha=0.3, jitter=True);

sns.swarmplot(x='Survived', y='Fare', data=df_train);

要点:票价显然与铁达尼号的生存息息相关。
- 使用DataFrame方法.describe()来检查”票价”作为生存函数的摘要统计信息。
df_train.groupby('Survived').Fare.describe()
| 计数 | 意思 | 小时 | 我 | 25% | 50% | 75% | 最大值 | |
|---|---|---|---|---|---|---|---|---|
| 幸存下来 | ||||||||
| 0 | 549.0 | 22.117887 | 31.388207 | 0.0 | 7.8542 | 10.5 | 26.0 | 263.0000 |
| 1 | 342.0 | 48.395408 | 66.596998 | 0.0 | 12.4750 | 26.0 | 57.0 | 512.3292 |
- 使用seaborn绘制”年龄”对”票价”的散点图, 并用”生存”着色。
sns.lmplot(x='Age', y='Fare', hue='Survived', data=df_train, fit_reg=False, scatter_kws={'alpha':0.5});

要点:似乎那些幸存者要么花了很多钱买票, 要么还年轻。
- 使用seaborn创建df_train的对图, 并用” Survived”着色。对图是一种在单个图网格中显示你已经发现的大多数信息的好方法。
sns.pairplot(df_train_drop, hue='Survived');

从EDA到机器学习模型
在本教程中, 你已成功:
- 加载我们的数据并进行了查看。
- 直观地探索了我们的目标变量, 并做出了第一个预测。
- 可视化地探索了我们的一些特征变量, 并根据我们的EDA做出了更好的预测。
- 对分类和数字特征变量进行了认真的EDA处理。
在下一篇文章中, 你将花时间根据在这里从EDA中学到的知识来构建一些机器学习模型。我们将在该项目的下一篇文章(将于12月27日发布)中进行此操作。



