本文概述
- 简介:R中的机器学习
- 步骤
- 将R用于k最近邻(KNN)
- 步骤1。获取你的数据
- 第二步。了解你的数据
- 第三步现在要去哪里?
- 第四步。准备工作区
- 第五步。准备数据
- 第六步。实际的KNN模型
- 第七步。模型评估
- 带有插入符号的R中的机器学习
- 转向大数据
简介:R中的机器学习
机器学习是计算机科学的一个分支, 致力于研究可以学习的算法的设计。典型的机器学习任务是概念学习, 功能学习或”预测建模”, 聚类和查找预测模式。这些任务是通过例如通过经验或说明观察到的可用数据来学习的。机器学习希望将经验纳入其任务中最终将改善学习。最终目标是以一种自动化的方式改进学习, 以使像我们这样的人不再需要干预。
本小教程旨在向你介绍R中机器学习的基础:更具体地说, 它将向你展示如何使用R与称为” KNN”或k最近邻的著名机器学习算法一起工作。
步骤
- 获取你的数据
- R的内置数据集
- 加州大学尔湾分校机器学习资料库
- 了解你的数据
- 数据集的初步概述
- 对数据的深刻理解
- 现在要去哪里。
- 准备工作区
- 准备数据
- 正常化
- 培训和测试集
- 实际的KNN模型
- 模型评估
- 带有插入符号的R中的机器学习
如果你对学习课程感兴趣, 请考虑阅读我们的《 R机器学习入门》或srcmini的R的无监督学习课程!
将R用于k最近邻(KNN)
KNN或k最近邻算法是最简单的机器学习算法之一, 并且是基于实例的学习的示例, 其中基于存储的标记实例对新数据进行分类。
更具体地, 借助于某种相似性度量来计算所存储的数据与新实例之间的距离。该相似性度量通常由诸如欧几里得距离, 余弦相似性或曼哈顿距离之类的距离度量来表达。
换句话说, 将为你输入到系统中的任何新数据点计算与系统中已有数据的相似性。
然后, 你可以使用此相似度值执行预测建模。预测建模可以是分类, 为新实例分配标签或类, 或者是回归, 为新实例分配值。是否分类或为新实例分配值当然取决于你如何使用KNN组合模型。
k最近邻算法在此基本算法上增加了一个新点到所有存储的数据点的距离已计算出之后, 对距离值进行排序并确定k最近邻。收集这些邻居的标签, 并使用多数票或加权票进行分类或回归。
换句话说, 已经存储的某个数据点的分数越高, 新实例接收与邻居实例相同分类的可能性就越大。在回归的情况下, 将分配给新数据点的值是其k个最近邻居的平均值。
步骤1。获取你的数据
机器学习通常从观察到的数据开始。你可以使用自己的数据集, 也可以浏览其他来源以找到一个。
R的内置数据集
本教程使用Iris数据集, 该数据集在机器学习领域非常著名。该数据集内置于R中, 因此你可以通过在控制台中键入以下内容来查看该数据集:
加州大学尔湾分校机器学习资料库
如果要下载数据集而不是使用R内置的数据集, 则可以转到UC Irvine机器学习存储库并查找Iris数据集。
提示:不仅要签出Iris数据集的数据文件夹, 还要看一下数据描述页面!
然后, 使用以下命令加载数据:
该命令从网站读取.csv或”逗号分隔值”文件。标头参数已设置为FALSE, 这意味着来自此源的虹膜数据集不会为你提供数据的属性名称。
当你使用诸如head()之类的函数检查iris属性时, 你可能会看到奇怪的列名称, 而不是属性名称, 例如” V1″或” V2″。这些是随机设置的。
为了简化使用数据集的工作, 一个好方法是自己创建列名:你可以通过函数names()来实现, 该函数获取或设置对象的名称。连接属性名称, 就像你希望它们出现一样。在上面的代码块中, 你将列出Sepal.Length, Sepal.Width, Petal.Length, Petal.Width和Species。
再说一次, 这些名称并非突如其来:看看上面链接的数据集的描述;通常, 你会看到所有这些名称。
第二步。了解你的数据
现在, 你已经将Iris数据集加载到RStudio中, 你应该尝试全面了解数据的含义。仅查看或阅读你的数据当然还不够开始!
如果你觉得数据太麻烦了, 你需要动手, 探索和可视化数据集, 甚至收集更多领域知识。
可能你已经具备了所需的领域知识, 但提醒一下, 所有花朵都包含萼片和花瓣。萼片包围花瓣, 并且通常是绿色的和叶状的, 而花瓣通常是有色的叶子。对于鸢尾花, 这只是有些不同, 如下图所示:

数据集的初步概述
首先, 你已经可以通过制作一些图表(例如直方图或箱形图)来了解数据。但是, 在这种情况下, 散点图可以让你对正在处理的内容有个很好的了解:查看一个变量受另一个变量的影响可能会很有趣。
换句话说, 你想查看两个变量之间是否存在任何关联。
例如, 你可以使用ggvis软件包进行散点图绘制。
请注意, 你首先需要加载ggvis软件包:
# Load in `ggvis`
library(ggvis)
# Iris scatter plot
iris %>% ggvis(~Sepal.Length, ~Sepal.Width, fill = ~Species) %>% layer_points()
你会看到Setosa鸢尾花的萼片长度和萼片宽度之间有很高的相关性, 而Virginica和Versicolor花的相关性则略低:数据点在图中分布得更多, 而没有形成一个簇, 就像在Setosa花朵中所见。
映射花瓣长度和花瓣宽度的散点图讲述了一个类似的故事:
iris %>% ggvis(~Petal.Length, ~Petal.Width, fill = ~Species) %>% layer_points()
你会看到, 该图表明了鸢尾花数据集所包含的所有不同物种的花瓣长度和花瓣宽度之间的正相关。当然, 如果你要真正确定这一点, 则可能需要进一步检验该假设:
你会看到, 将所有三个种类组合在一起时, 其相关性比分别查看不同种类时的相关性要强一些:整体相关性为0.96, 而对于Versicolor, 则为0.79。另一方面, 将数字四舍五入时, Setosa和Virginica的花瓣长和宽的相关性分别为0.31和0.32。
提示:你对ggvis, 图形或直方图特别好奇吗?查看我们的直方图教程和/或ggvis课程。
在对数据进行一般的可视化概述之后, 你还可以通过输入以下内容来查看数据集:
但是, 正如你从该命令的结果中看到的那样, 这确实不是彻底检查数据集的最佳方法:该数据集在控制台中占用了大量空间, 这将妨碍你形成清晰的想法关于你的数据。因此, 最好通过执行head(iris)或str(iris)来检查数据集。
请注意, 最后一条命令将帮助你清楚地区分数据类型num和Species属性的三个级别, 这是一个因素。这非常方便, 因为许多R机器学习分类器要求将目标特征编码为一个因素。
请记住, 因子变量代表R中的类别变量。因此, 它们可以具有有限数量的不同值。
快速浏览”物种”属性可知, 花朵的物种划分为50-50-50。另一方面, 如果要检查”种类”属性的百分比划分, 则可以要求一个比例表:
请注意, round参数将第一个参数prop.table(table(iris $ Species))* 100的值四舍五入为指定的位数, 该位数是小数点后的一位。你可以通过更改digits参数的值来轻松调整此值。
对数据的深刻理解
让我们不要停留在数据的高级概述中! R使你有机会更深入地使用summary()函数。这将为你提供数值数据类型的数据集Iris的最小值, 第一分位数, 中位数, 均值, 第三分位数和最大值。对于类变量, 将返回因子计数:
如你所见, c()函数被添加到原始命令中:列花瓣宽度和间隔宽度被串联, 然后仅对Iris数据集的这两列询问摘要。
第三步现在要去哪里?
对数据有充分的了解之后, 你必须决定与数据集相关的用例。换句话说, 你考虑数据集可能会教给你什么, 或者你认为可以从数据中学到什么。从那里开始, 你可以考虑可以将哪种算法应用于数据集, 以便获得你认为可以获得的结果。
提示:请记住, 你对数据越熟悉, 就越容易评估特定数据集的用例。寻找合适的机器算法也是如此。
在本教程中, 将使用Iris数据集进行分类, 这是预测建模的一个示例。数据集的最后一个属性Species将是目标变量或在此示例中你要预测的变量。
请注意, 如果要使用KNN进行回归, 也可以将数字类之一用作目标变量。
第四步。准备工作区
R默认未将机器学习中使用的许多算法合并到R中。你最可能需要在开始学习机器学习时下载要使用的软件包。
提示:了解你可能使用的学习算法, 但不知道你想要或需要的哪个程序包?你可以在这里找到R中使用的所有软件包的完整概述。
为了说明KNN算法, 本教程将使用package类:
如果你还没有此软件包, 则可以通过键入以下代码行来快速轻松地做到这一点:
install.packages("<package name>")请记住书呆子提示:如果不确定是否有此软件包, 可以运行以下命令来查找!
any(grepl("<name of your package>", installed.packages()))第五步。准备数据
探索数据并准备好工作区之后, 你最终可以将精力集中在前面的任务上:建立机器学习模型。但是, 在执行此操作之前, 还必须准备数据, 这一点很重要。下一节将概述执行此操作的两种方法:标准化数据(如有必要)以及将数据拆分为训练集和测试集。
正常化
作为数据准备的一部分, 你可能需要规范化数据以使其一致。对于本入门教程, 请记住, 归一化使KNN算法更容易学习。归一化有两种类型:
- 示例规范化是每个示例的单独调整, 而
- 功能规范化表示你在所有示例中都以相同的方式调整了每个功能。
那么什么时候需要规范化数据集呢?
简而言之:当你怀疑数据不一致时。
当你浏览summary()函数的结果时, 可以轻松地看到这一点。查看所有(数字)属性的最小值和最大值。如果看到一个属性具有广泛的值范围, 则需要对数据集进行规范化, 因为这意味着距离将由该功能控制。
例如, 如果你的数据集只有两个属性, 即X和Y, 并且X的值范围从1到1000, 而Y的值范围只有1到100, 那么Y对距离函数的影响通常会被抵消X的影响力。
进行归一化时, 实际上是在调整所有功能的范围, 因此不会过分强调具有较大范围的变量之间的距离。
提示:返回summary(iris)的结果, 然后尝试确定是否需要规范化。
Iris数据集无需标准化:Sepal.Length属性的值从4.3到7.9, Sepal.Width的值从2到4.4, 而Petal.Length的值的范围从1到6.9, 而Petal.Width从0.1到2.5。所有属性的所有值都包含在0.1到7.9的范围内, 你可以认为可接受。
不过, 学习规范化及其效果仍然是一个好主意, 尤其是如果你不熟悉机器学习。你可以执行功能规范化, 例如, 首先创建自己的normalize()函数。
然后, 你可以在另一个命令中使用此参数, 在该函数中, 在函数lapply()返回与你提供的数据集长度相同的列表之后, 通过as.data.frame()将规范化结果放入数据帧中in。该列表的每个元素都是将normalize参数应用于作为输入的数据集的结果:
YourNormalizedDataSet <- as.data.frame(lapply(YourDataSet, normalize))在下面的srcmini Light块中对此进行测试!
对于Iris数据集, 你将对Iris数据集的四个数值属性(Sepal.Length, Sepal.Width, Petal.Length, Petal.Width)应用normalize参数, 并将结果放入数据框中。
提示:为更全面地说明标准化对数据集的影响, 请将以下结果与第二步中给出的Iris数据集的摘要进行比较。
培训和测试集
为了稍后评估模型的性能, 你需要将数据集分为两部分:训练集和测试集。
第一个用于训练系统, 而第二个用于评估学习或训练的系统。实际上, 将数据集分为测试集和训练集是不相交的:最常见的拆分选择是将原始数据集的2/3作为训练集, 而剩下的1/3将组成测试集。
对数据集的最后一眼告诉你, 如果按原样对数据集进行两组划分, 你将获得包含” Setosa”和” Versicolor”所有种类的培训课程, 但没有” Virginica”的所有课程。该模型因此会将所有未知实例分类为” Setosa”或” Versicolor”, 因为它不会知道数据中是否存在第三种花。
简而言之, 你将对测试集获得不正确的预测。
因此, 你需要确保训练模型中存在所有三类物种。此外, 所有这三种物种的实例数量必须大致相等, 以免在预测中不偏向另一类。
要进行训练和测试, 首先要设置一个种子。这是R的随机数生成器的数量。设置种子的主要优点是, 只要在随机数生成器中提供相同的种子, 就可以获得相同的随机数序列。
set.seed(1234)然后, 你要确保对Iris数据集进行了改组, 并且在训练和测试集中每种物种的数量相同。
你使用sample()函数以设置为Iris数据集的行数或150的大小进行采样。进行替换采样:你从2个元素的向量中进行选择, 并指定1或2到Iris数据集的150行。元素的分配服从0.67和0.33的概率权重。
ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.67, 0.33))请注意, replace参数设置为TRUE:这意味着你将1或2分配给特定的行, 然后将2的向量重置为其原始状态。这意味着, 对于数据集中的下一行, 你可以再次分配1或2。选择1或2的概率不应与其余项之间的权重成正比, 因此你可以指定概率权重。另请注意, 即使你没有在srcmini Light块中看到它, 种子仍设置为1234。
请记住, 你希望训练集为原始数据集的2/3:这就是为什么要为150个样本行分配概率为0.67的” 1″和概率为0.33的” 2″。
然后, 你可以使用存储在变量ind中的样本来定义你的训练和测试集:
请注意, 除了上面指定的2/3和1/3比例外, 你没有考虑所有属性来构成训练和测试集。具体来说, 你只需要输入Sepal.Length, Sepal.Width, Petal.Length和Petal.Width。这是因为你实际上要预测第五个属性Species:它是你的目标变量。但是, 你确实希望将其包括在KNN算法中, 否则永远不会有任何预测。
因此, 你需要将类别标签存储在因子向量中, 并将它们划分为训练集和测试集:
第六步。实际的KNN模型
建立分类器
在完成所有这些准备步骤之后, 请确保已存储所有已知(培训)数据。直到这一刻为止, 还没有进行任何实际的模型或学习。现在, 你要查找训练集中的k个最近邻居。
完成这两个步骤的一种简单方法是使用knn()函数, 该函数使用Euclidian距离度量来查找新的未知实例的k个近邻。在这里, k参数是你自己设置的参数。
如前所述, 通过查看多数表决或加权表决对新实例进行分类。在分类的情况下, 得分最高的数据点将赢得战斗, 未知实例将获得该获胜数据点的标签。如果获奖者人数相等, 则分类随机发生。
注意:k参数通常是一个奇数, 以避免在投票分数中产生联系。
要构建你的分类器, 你需要使用knn()函数, 并向其添加一些参数, 就像在此示例中一样:
你将knn()函数存储到iris_pred中, 该函数将训练集, 测试集, 训练标签以及你要使用此算法查找的邻居数量作为参数。该函数的结果是一个因子向量, 其中包含测试数据每一行的预测类。
请注意, 你不想插入测试标签:这些标签将用于查看你的模型是否擅长预测实例的实际类!
你会看到, 在检查结果iris_pred时, 你将获得带有测试数据每一行预测类别的因子向量。
第七步。模型评估
机器学习中至关重要的下一步就是评估模型的性能。换句话说, 你想分析模型预测的正确性。
对于更抽象的视图, 你可以将iris_pred的结果与之前定义的测试标签进行比较:
你会看到, 该模型做出了合理准确的预测, 但在第29行中有一个错误的分类, 其中在测试标签为” Virginica”时预测为” Versicolor”。
这已经预示了模型的性能, 但是你可能想更深入地分析。为此, 你可以导入包gmodels:
install.packages("package name")但是, 如果你已经安装了此软件包, 则只需输入
library(gmodels)然后, 你可以制作交叉表或列联表。此类表通常用于了解两个变量之间的关系。在这种情况下, 你想了解存储在iris.testLabels中的测试数据的类与存储在iris_pred中的模型之间的关系:
CrossTable(x = iris.testLabels, y = iris_pred, prop.chisq=FALSE)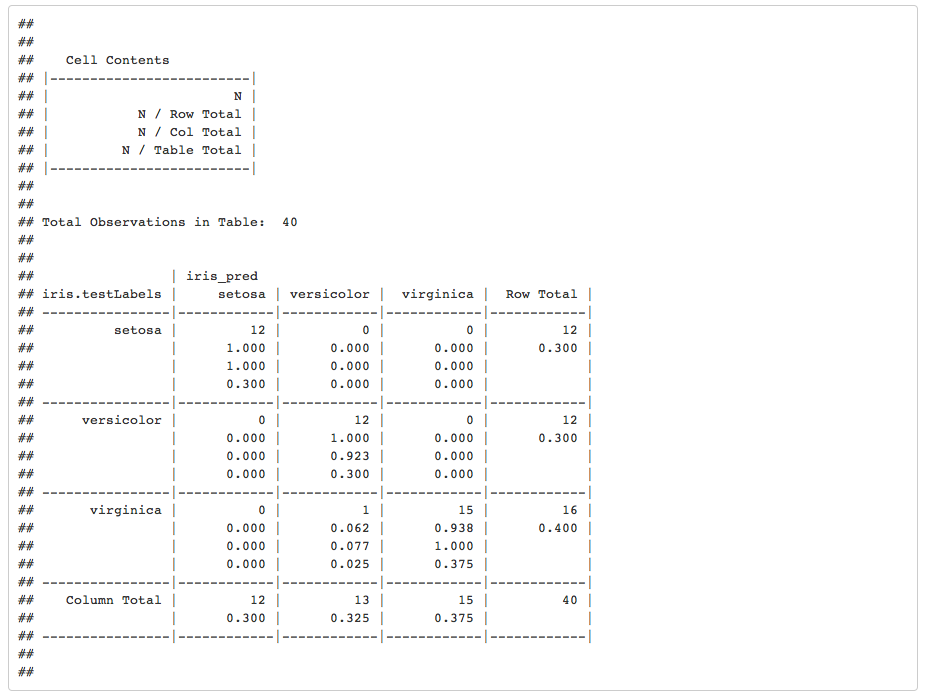
请注意, 最后一个参数prop.chisq指示是否包括每个单元的卡方贡献。卡方统计量是每个单个单元的贡献之和, 用于确定观察值与期望值之间的差异是否显着。
从该表中, 你可以得出正确和不正确的预测数:测试集中的一个实例被模型标记为Versicolor, 而实际上是维珍妮卡花。你可以在iris.testLabels列中的” Virginica”种类的第一行中看到此内容。在所有其他情况下, 都做出了正确的预测。你可以得出结论, 该模型的性能足够好, 不需要改进模型!
带有插入符号的R中的机器学习
在前面的部分中, 你已经开始通过KNN算法在R中进行监督学习。正如你可能没有在上面看到的那样, R中的机器学习会变得非常复杂, 因为存在各种具有不同语法, 不同参数等的算法。当我说记住每种算法的不同程序包名称时, 也许你会同意我的看法可能会变得非常困难, 或者将语法应用于每种特定算法实在太多了。
这是插入符号包可以派上用场的地方:它是”分类和回归训练”的缩写, 并且提供解决有监督的机器学习问题所需的一切:它为大量机器学习算法提供了统一的界面。如果你对Python机器学习有所了解, 可能会发现与scikit-learn有相似之处!
在下文中, 你将按照上面概述的步骤进行操作, 但是这次, 你将使用插入符号对数据进行分类。请注意, 如果你按照上面概述的步骤进行操作, 则你已经完成了很多工作:你已经拥有了数据, 已经浏览了数据, 准备了工作区, 等等。现在该对数据进行预处理了用插入号!
像以前一样, 你可以研究标准化的效果, 但是稍后将在本教程中看到。
你已经知道接下来要做什么!让我们将数据分成训练和测试集中。但是, 在这种情况下, 处理方式略有不同:你根据在iris $ Species中找到的标签拆分数据。同样, 在这种情况下, 训练和测试集的比率设置为75-25。
大家都准备去训练模型!但是, 你可能还记得, 插入符号是一个非常大的项目, 其中包含许多算法。如果你对项目中包含的算法有疑问, 可以获取所有算法的列表。通过运行名称(getModelInfo())来拉列表, 就像下面的代码块所示。接下来, 选择一个算法并使用train()函数训练模型:
请注意, 到目前为止, 制作其他模型非常简单。你只需要更改method参数, 就像下面的示例一样:
model_cart <- train(iris.training[, 1:4], iris.training[, 5], method='rpart2')现在, 你已经训练了模型, 是时候预测刚刚制作的测试集的标签并评估模型如何处理数据了:
此外, 你可以尝试执行与以前相同的测试, 以检查预处理对模型的影响, 例如缩放和居中。运行以下代码块:
转向大数据
恭喜你!你已经完成了本教程!
本教程主要涉及在R的帮助下执行基本的机器学习算法KNN。使用的Iris数据集很小且可概述。你不仅看到了如何自己执行所有步骤, 而且还看到了如何轻松使用统一的界面(如插入符号提供的界面)来激发你的机器学习。
但是你可以做的更多!
如果你已经对本教程中介绍的基础知识和其他机器学习算法进行了充分的实验, 则可能会发现进一步进入R和数据分析很有趣。



