本文概述
数据可能很复杂, 乏味, 有时发现模式可能很困难。考虑一种情况, 你有一些属于公司的销售数据。你想发现一种有关消费者消费能力的模式。如果你可以发现数据中不同的组或关联, 则可以相应地定位不同的组以获取最大的销售额。这种直觉背后的基本思想称为聚类, Tableau具有一个固有功能, 可以根据某些属性自动将相似的数据点聚类。让我们探索Tableau的此功能, 看看如何将聚类应用于实际数据集。
K均值聚类
聚类(也称为聚类分析)是一种无监督的机器学习算法, 它倾向于基于相似性度量将相似的项目组合在一起。
Tableau在后台使用K均值聚类算法。 K均值是将数据分为K个群集并属于基于质心的群集的一种群集技术。在K均值聚类中, 对于给定数目的聚类k, 该算法将数据集拆分为k个聚类, 其中每个聚类都有一个质心, 质心的计算方法是该聚类中所有点的平均值。然后, 根据数据点与质心的距离对数据点进行聚类。
这是有关srcmini的两个很棒的教程, 详细介绍了群集的概念:
- 使用scikit-learn在Python中进行K-Means聚类
- R教程中的K均值聚类
如果你想了解有关机器学习中的集群的更多信息, 请参加srcmini的Python无监督学习或带有SciPy的集群方法课程。
下图将K -Means算法可视化以更好地理解。最初, 我们随机定义4个质心点。然后, K均值算法将每个数据点分配给其最近的聚类(叉)。当所有数据点的平均值都改变时, 质心将移动到新位置, 并且重复整个过程, 直到我们观察到质心的位置不再发生变化为止。

可视化K-Means算法
Tableau中的聚类标准
了解集群方法后, 现在让我们了解Tableau是如何完成集群的。 Tableau使用Calinski-Harabasz准则评估群集质量。这是Calinski-Harabasz准则的数学解释:

资源
“其中SSB是总体集群间方差, SSW是总体集群内方差, k是集群数, 而N是观察数”(来源)。
该比率给出确定簇的内聚性的值。因此, 该值越高, 群集之间的距离越近, 群集之间的距离就越小。
先决条件
本文假定你对Tableau有所了解。如果你是一个完整的初学者, 建议你阅读以下有关srcmini的文章, 该文章是出色的入门。
使用Tableau进行数据可视化
Tableau环境
在本教程中, 我们将使用Tableau Public, 这是Tableau的绝对免费产品。从官方网站下载Tableau Public版本。请按照安装说明进行操作, 并且如果在单击Tableau图标时出现以下屏幕, 则可以执行。

连接到数据集
我们将在本文中使用的数据集称为”世界经济指标”数据集。该数据集包括一些推动经济发展的重要指标, 例如各国的预期寿命, 经商难易程度, 人口等。它是从联合国获得的。可以从此处访问数据集。
- 将数据集下载到你的系统上。
- 从计算机将数据导入到Tableau工作区中。使用”工作表”选项卡下的”数据解释器”纠正和重新对齐数据。
格式化数据源
转到工作表, 然后浏览”度量和尺寸”选项卡。 “度量”选项卡下有很多功能, 可以将其合并为一个类别。这也将有助于更好地表示所有数据字段。
- 选择”营业税率”, “开始营业的天数”, “营业便利性”, “营业税和贷款利息小时数”>”创建文件夹”。
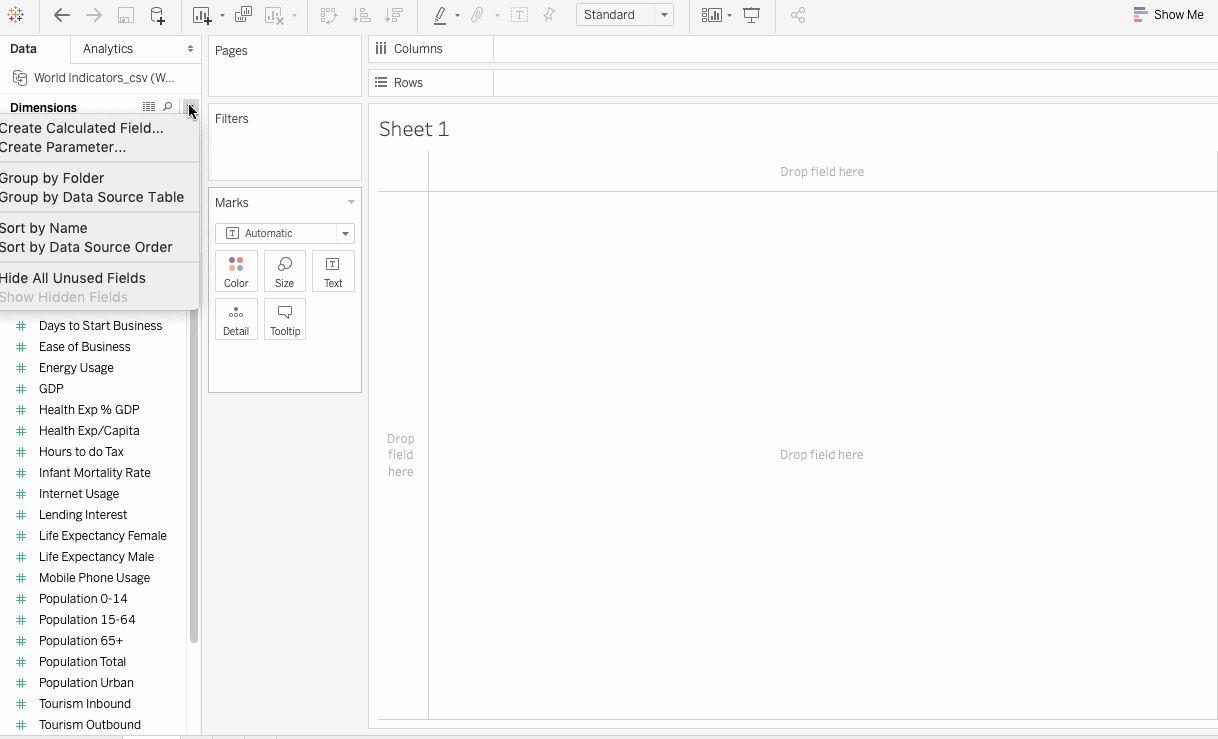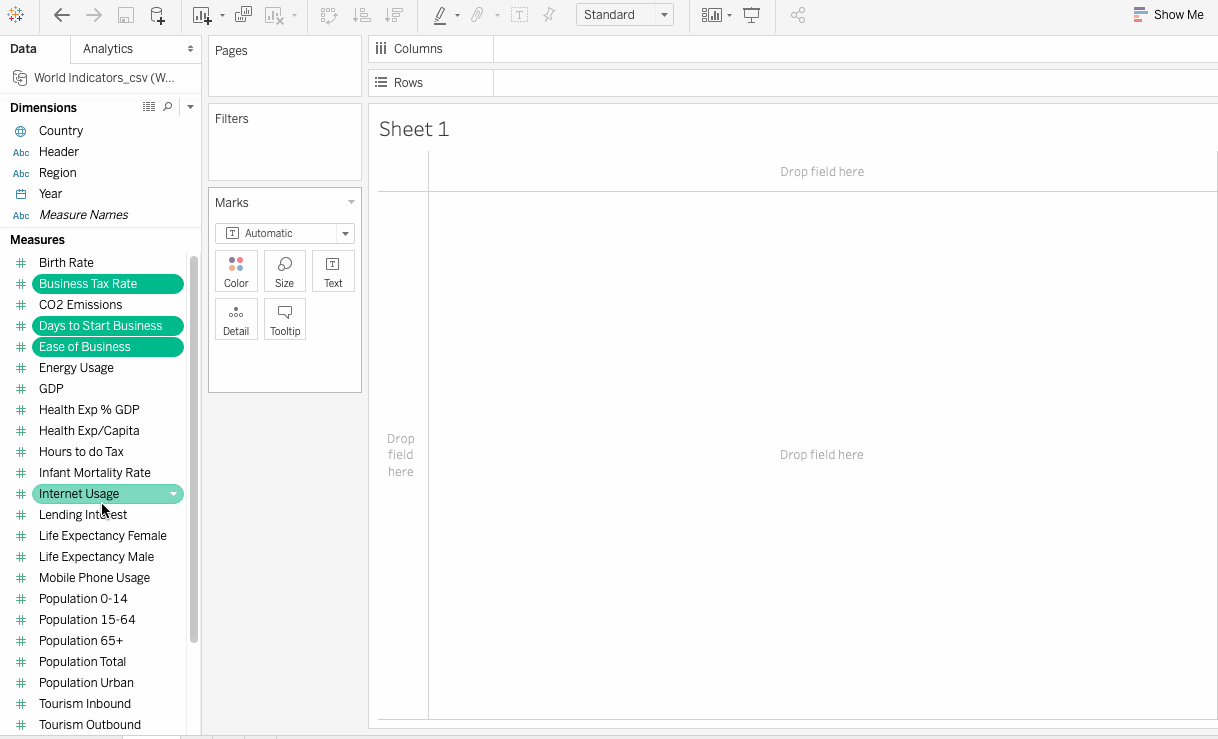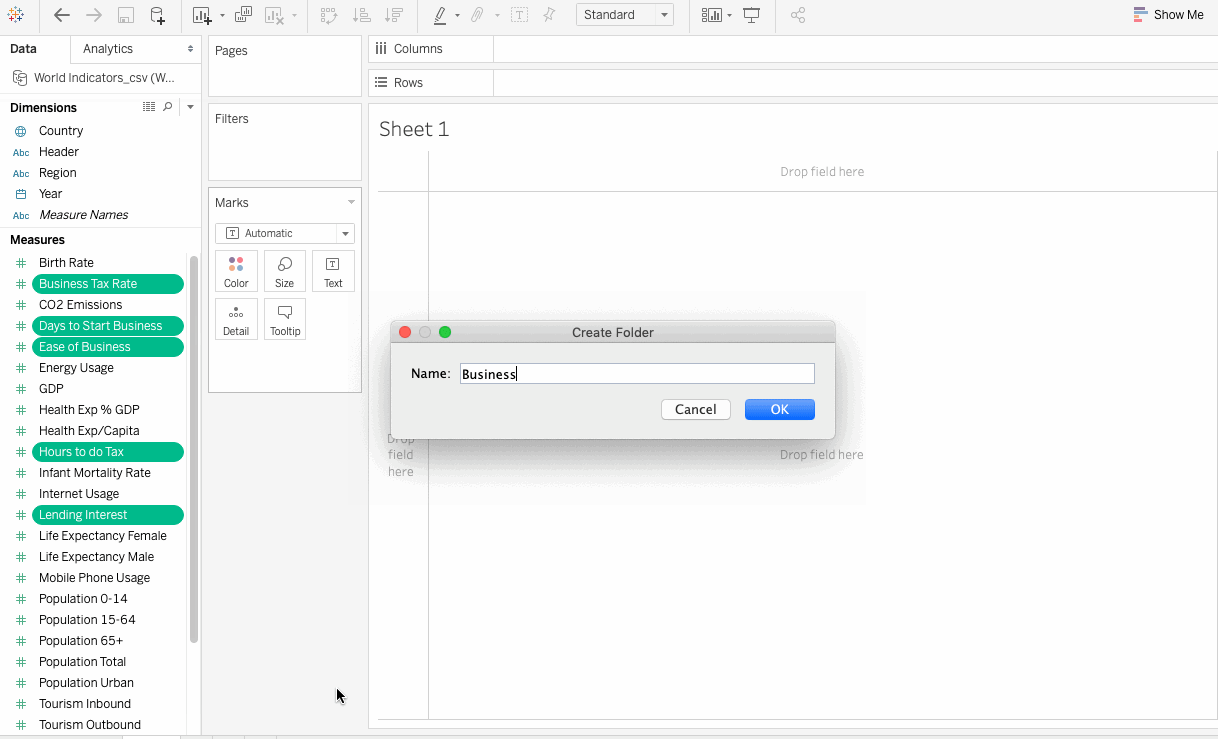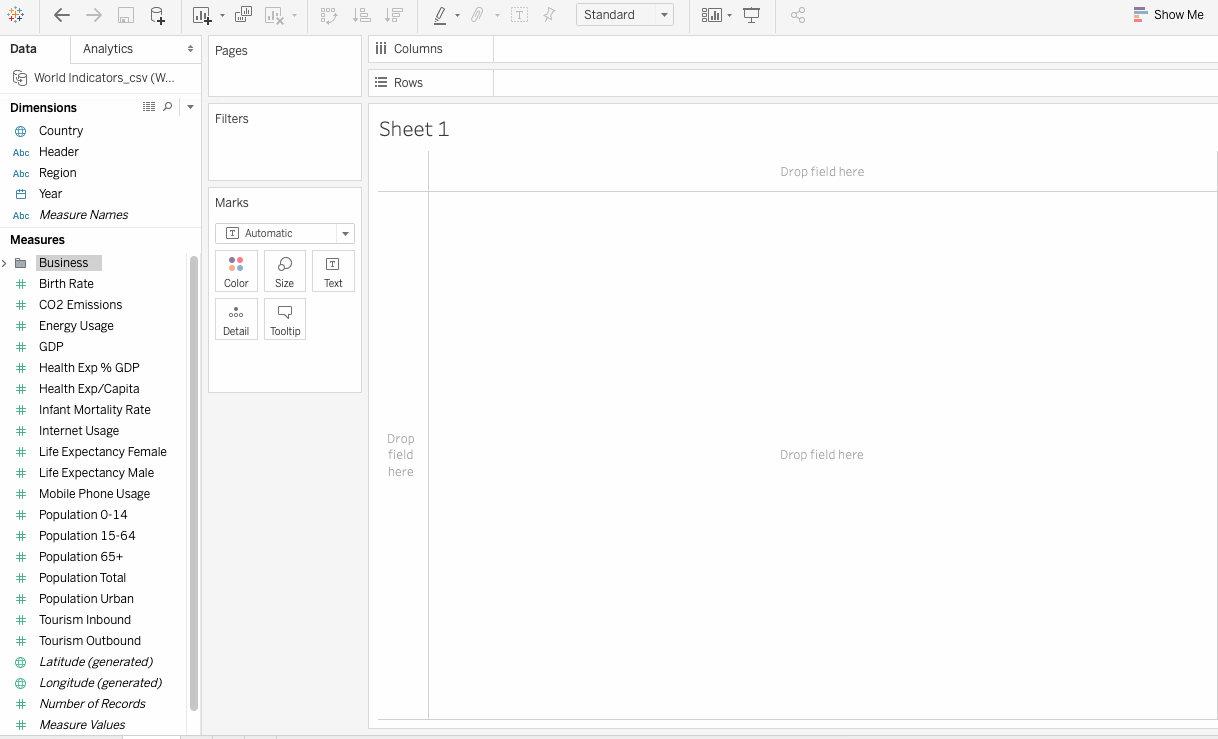
- 将文件夹命名为Business, 现在所有上述字段都包含在此特定文件夹中。

- 同样, 为”发展”, “健康”和”人口”创建文件夹。另外, 分别添加以下字段。格式化后, “度量”选项卡如下所示:
根据世界经济指标数据创建集群
聚类有助于发现数据集中的模式。假设你是某旅游公司的分析师。由于世界各地预期寿命的增加, 高级旅游业激增。现在, 老年人更加活跃, 并且对旅行和游览世界更加感兴趣。你的公司正在尝试从这种现象中获利, 你的工作是使用”世界指标”样本数据来识别有足够合适客户类型的国家/地区。聚类是可以帮助我们识别这类国家的工具。
确定高级旅游成功率高的国家
现在, 我们完成各个步骤以对数据执行聚类分析。
- 在”数据”窗格下的”维度”中双击”国家/地区”。 Tableau创建一个地图视图, 并用实心圆表示每个国家/地区。在”标记”卡上, 将标记类型更改为”地图”,

确定聚类变量
聚类的下一步是确定将在聚类算法中使用的变量。在Tableau中, 变量类似于字段。给出理想聚类的最佳变量并没有唯一的答案, 但是你可以尝试使用多个变量来查看产生期望结果的变量。在我们的情况下, 让我们处理以下字段:
- 城市人口
城市人口是一个国家人口密度的良好指标。密度越高, 可用的商机就越多。
- 人口65+
65岁以上的人口表示老年人, 这也是我们的目标人群。
- 女性预期寿命, 男性预期寿命
预期寿命较高的国家表示那里的人寿命更长, 并且对旅行更加感兴趣。
- 人均旅游
该字段不存在, 可以使用”旅游出站”和”人口总数”字段将其创建为计算字段, 如下所示:
人均旅游人数= SUM([旅游出站])/ SUM([人口总数])

旅游出境代表一个国家的人每年在国际旅行上花费的金钱(美元)。为了获得平均值, 我们需要将该字段除以每个国家的人口。
将所选字段添加到视图
在继续之前, 我们需要将默认聚合从SUM更改为AVERAGE。 Tableau使汇总度量或维度成为可能, 尽管汇总度量更为常见。每当我们向视图添加度量时, 默认情况下都会将聚合应用于该度量。需要应用的聚合类型取决于视图的上下文。

更改所有选定字段的聚合, 然后将其拖到”标记”卡上的”详细信息”, 如下所示:

聚类
Tableau中的群集是一个简单的拖放过程。以下步骤概述了群集过程:
- 单击”分析窗格”, 然后将”群集”拖动到视图上, Tableau会自动将数据群集。

- 尽管Tableau可以自动确定要创建的群集数量, 但我们也可以控制群集的数量以及用于计算群集的变量。只需在框中拖动一个字段以将其包括在聚类算法中, 或将其拖出以将其排除。

- 我们将使用4个群集和默认变量, 以进行更好的分析。请注意, 一些国家/地区不属于任何类别, 因此被标记为未分组。

- 该簇被创建为新药丸, 并且可以在颜色架子上看到。将此药丸拖到”数据窗格”上, 以保存为一组。

因此, 在这里, 我们根据选择的措施对国家进行了分类。但是, 我们如何从这些结果中弄清楚, 又如何根据集群做出业务决策?下一节将解决这些问题。
描述集群
单击标记卡中的”群集”字段, 然后单击”描述群集”选项。

这将显示一个文档, 其中包含有关群集的详细说明。该文档中有两个选项卡:
摘要
这给出了结果的汇总以及每个聚类的每个变量的平均值。

根据以上结果, 我们可以推断出集群3具有:
- 男性和女性的最高预期寿命
- 人均旅游总人数最高
- 最高城市人口
这意味着它有一个富裕的城市人口, 具有较高的预期寿命, 因此对于高级旅游业来说似乎是一个很好的市场。让我们看看该集群中包括哪些国家。

楷模
“模型”标签显示所有变量/字段的平均值的各种统计值, 并显示其统计意义。

因此, 作为分析师, 你可以将此列表呈现给销售团队, 以便他们可以专注于这些潜在客户。集群为我们提供了深刻的见识。从这里, 你可以尝试不同的字段, 设置人口或收入的阈值等。有许多方法可以对数据进行聚类, 但是基本原理保持不变。
总结
在本文中, 我们学习了如何使用简单的拖放机制对Tableau中的给定数据集执行聚类分析。聚类是一种有价值的工具, 当与Tableau结合使用时, 聚类可以使分析人员掌握统计分析技术的功能。
参考文献
文件表



