本文概述

深度学习是机器学习的一个子领域, 它是一组受大脑结构和功能启发的算法。
TensorFlow是Google创建并用于设计, 构建和训练深度学习模型的第二个机器学习框架。你可以使用TensorFlow库来进行数值计算, 虽然看起来似乎并不特殊, 但是这些计算是通过数据流图完成的。在这些图中, 节点表示数学运算, 而边沿表示数据, 通常是多维数据数组或张量, 在这些边沿之间进行通信。
你看?名称” TensorFlow”源自神经网络对多维数据数组或张量执行的操作!它实际上是张量流。目前, 这只是张量所需的全部知识, 但是在下一部分中, 你将更深入地了解这一点!
今天面向初学者的TensorFlow教程将向你介绍如何以交互方式进行深度学习:
- 你将首先了解有关张量的更多信息;
- 然后, 本教程将简要介绍一些在系统上安装TensorFlow的方法, 以便你可以入门并在工作区中加载数据;
- 之后, 你将了解一些TensorFlow基础知识:你将看到如何轻松地从简单的计算开始。
- 之后, 你就可以开始实际工作了:你将加载比利时交通标志的数据, 并通过简单的统计数据和绘图对其进行探索。
- 在你的探索中, 你会发现有必要以一种可以将其输入模型的方式来处理数据。这就是为什么你要花时间重新缩放图像并将其转换为灰度图像的原因。
- 接下来, 你终于可以开始使用神经网络模型了!你将在每个图层上构建模型图层;
- 架构设置完成后, 你可以使用它来交互地训练模型, 并最终通过向其提供一些测试数据来对其进行评估。
- 最后, 你将获得一些建议, 可以进一步完善你刚刚构建的模型, 以及如何继续使用TensorFlow学习。
在此处下载本教程的笔记本。
另外, 你可能对Python深度学习, srcmini的Keras教程或带R的keras教程感兴趣。
张量介绍
为了更好地理解张量, 最好具有线性代数和矢量演算的一些应用知识。你已经在介绍中阅读了TensorFlow中将张量实现为多维数据数组的信息, 但是可能需要更多介绍才能完全掌握张量及其在机器学习中的使用。
平面向量
在研究平面向量之前, 最好先修改一下”向量”的概念;向量是特殊类型的矩阵, 是数字的矩形阵列。因为向量是数字的有序集合, 所以它们通常被视为列矩阵:它们只有一列和一定数量的行。换句话说, 你也可以将向量视为已指定方向的标量。
请记住:标量的示例是” 5米”或” 60 m / sec”, 而矢量例如是”北5米”或”东60 m / sec”。两者之间的区别显然是向量具有方向。不过, 你到目前为止所看到的这些示例似乎与处理机器学习问题时可能遇到的向量相差很远。这是正常的;数学向量的长度是一个纯数字:绝对值。另一方面, 方向是相对的:相对于某个参考方向进行测量, 并以弧度或度为单位。通常, 你假设方向为正, 并且相对于参考方向为逆时针旋转。
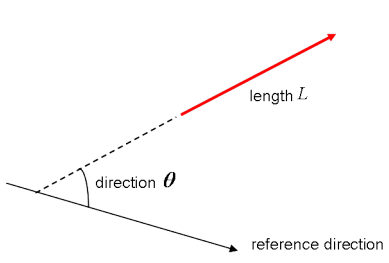
当然, 在视觉上, 你将向量表示为箭头, 如上图所示。这意味着你也可以将向量视为具有方向和长度的箭头。方向由箭头的头部指示, 而长度由箭头的长度指示。
那么, 平面向量呢?
平面向量是张量最直接的设置。它们就像你在上面看到的常规向量一样, 唯一的区别是它们位于向量空间中。为了更好地理解这一点, 让我们从一个示例开始:你有一个2 X 1的向量。这意味着该向量属于一次成对配对的实数集。或者, 换句话说, 它们是两个空间的一部分。在这种情况下, 可以用箭头或射线在坐标(x, y)平面上表示矢量。
从该坐标平面的标准位置开始, 矢量的端点在原点(0, 0), 可以通过查看矢量的第一行来得出x坐标, 而在第二行中可以找到y坐标行。当然, 并不总是需要保持此标准位置:向量可以在平面中平行于自身移动而不会发生变化。
请注意, 类似地, 对于大小为3 X 1的向量, 你将讨论三个空间。你可以将矢量表示为三维图形, 并用箭头指向矢量步速中的位置:它们在标准的x, y和z轴上绘制。
拥有这些向量并在坐标平面上表示它们是很好的, 但是本质上, 你拥有这些向量, 以便可以对它们执行操作, 而可以帮助你完成此操作的一件事是通过将向量表示为基数或单位向量。
单位向量是大小为1的向量。你通常会通过带有抑音符或”帽子”的小写字母来识别单位向量。如果要将2-D或3-D矢量表示为两个或三个正交分量(例如x和y轴或z轴)的总和, 则单位矢量会很方便。
而且, 当你谈论将一个向量表示为例如分量的和时, 你会看到你正在谈论的是分量向量, 这是两个或多个向量, 其和为给定向量。
提示:观看此视频, 该视频通过简单的家用物品解释张量是什么!
张量
除了平面向量, 协向量和线性算子也是另外两种情况, 这三种情况共同具有一个共同点:它们是张量的特定情况。你仍然记得上一节中如何将矢量描述为已给出方向的标量。那么, 张量是物理实体的数学表示, 可以用大小和多个方向来表征。
而且, 例如, 就像在3维空间中表示一个具有单个数字的标量和一个具有三个数字序列的向量一样, 张量可以由3维空间中的3R数字数组表示。
此符号中的” R”代表张量的等级:这意味着在三维空间中, 第二等级张量可以由3表示2或9的幂。在N维空间中, 标量仍将只需要一个数, 而向量将需要N个数, 张量将需要N ^ R个数。这解释了为什么你经常听到标量是等级0的张量的原因:由于它们没有方向, 因此可以用一个数字表示它们。
考虑到这一点, 识别标量, 向量和张量并将它们分开相对容易:标量可以由单个数字表示, 向量可以由有序数字集表示, 张量可以由数字数组表示。
使张量如此独特的是分量和基向量的组合:基向量在参考帧之间进行一种转换, 而分量以使分量和基向量之间的组合保持相同的方式进行转换。
安装TensorFlow
现在, 你对TensorFlow有了更多的了解, 是时候开始并安装该库了。在这里, 很高兴知道TensorFlow提供了适用于Python, C ++, Haskell, Java, Go, Rust的API, 并且还有用于R的第三方软件包tensorflow。
提示:如果你想进一步了解R中的深度学习包, 请考虑查看srcmini的keras:R教程中的深度学习。
在本教程中, 你将下载TensorFlow的版本, 该版本使你能够使用Python编写深度学习项目的代码。在TensorFlow安装网页上, 你会看到一些使用virtualenv, pip, Docker安装TensorFlow的最常用方法和最新说明, 最后还有在个人计算机上安装TensorFlow的其他方法。
注意如果你使用的是Windows, 则还可以将TensorFlow与Conda一起安装。但是, 由于TensorFlow的安装受社区支持, 因此最好查看官方安装说明。
现在, 你已经完成了安装过程, 是时候通过将别名导入到工作区tf中来仔细检查你是否已正确安装TensorFlow:
import tensorflow as tf请注意, 你在上面的代码行中使用的别名是一种约定-用于确保你一方面与在数据科学项目中使用TensorFlow的其他开发人员保持一致, 并与开源TensorFlow项目保持一致另一方面。
TensorFlow入门:基础知识
通常, 你将编写TensorFlow程序, 它们作为一个块运行;乍看之下, 使用Python时这是矛盾的。但是, 如果你愿意, 也可以使用TensorFlow的交互式会话, 该会话可用于与库进行更多交互。当你习惯使用IPython时, 这特别方便。
在本教程中, 你将专注于第二个选项:这将帮助你开始使用TensorFlow中的深度学习。但是, 在继续进行此操作之前, 让我们先尝试一些次要的东西, 然后再开始进行繁重的工作。
首先, 如上一节所述, 在别名tf下导入tensorflow库。然后初始化两个实际上是常量的变量。将四个数字组成的数组传递给constant()函数。
请注意, 你还可以传入一个整数, 但更多情况下, 你会发现自己正在使用数组。如你在简介中所见, 张量与数组有关!因此, 请确保你传入一个数组:)接下来, 你可以使用乘法()将两个变量相乘。将结果存储在结果变量中。最后, 借助print()函数打印出结果。
请注意, 你已经在上面的srcmini Light代码块中定义了常量。但是, 还可以使用其他两种类型的值, 即占位符, 它们是未分配的值, 运行时将由会话初始化。就像已经给出的名称一样, 它只是张量的占位符, 将在运行会话时始终被填充;还有变量, 它们是可以更改的值。你可能已经收集到的常数是不变的值。
代码行的结果是计算图中的抽象张量。但是, 与你预期的相反, 该结果实际上并未得到计算。它只是定义了模型, 但没有运行任何过程来计算结果。你可以在打印输出中看到这一点:实际上并没有想要看到的结果(即30)。这意味着TensorFlow的评估很懒!
但是, 如果你确实想查看结果, 则必须在交互式会话中运行此代码。你可以通过几种方式来执行此操作, 如下面的srcmini Light代码块所示:
请注意, 你还可以使用以下代码行来启动交互式会话, 运行结果并在打印输出后再次自动关闭会话:
在上面的代码块中, 你已经定义了默认的会话, 但也很高兴知道你也可以传入选项。例如, 你可以指定config参数, 然后使用ConfigProto协议缓冲区为会话添加配置选项。
例如, 如果你添加
config=tf.ConfigProto(log_device_placement=True)在会话中, 请确保你记录分配给某个操作的GPU或CPU设备。然后, 你将获得会话中每个操作使用哪些设备的信息。例如, 在对设备放置使用软约束时, 也可以使用以下配置会话:
config=tf.ConfigProto(allow_soft_placement=True)既然你已经安装了TensorFlow并将其导入到工作区中, 并且已经了解了使用该软件包的基础知识, 那么现在该搁置片刻, 然后将注意力转移到数据上。与往常一样, 在开始对神经网络建模之前, 你首先需要花一些时间来更好地探索和理解数据。
比利时交通标志:背景
尽管流量是大家当中众所周知的话题, 但短暂浏览此数据集中包含的观察值以了解你是否在开始之前就了解了所有内容并没有什么害处。本质上, 在本节中, 你将快速掌握本教程中需要进一步学习的领域知识。
当然, 因为我是比利时人, 所以我将确保你还会得到一些轶事:)
- 比利时的交通标志通常使用荷兰语和法语。很高兴知道这一点, 但是对于你将要使用的数据集来说, 它并不是太重要!
- 比利时的交通标志分为六类:警告标志, 优先标志, 禁止标志, 强制性标志, 与在道路上停车和静止不动有关的标志, 以及最后的指示性标志。
- 2017年1月1日, 超过30, 000条比利时道路的交通标志被拆除。这些都是与速度有关的禁止标志。
- 关于撤离, 交通标志的大量存在一直是比利时(以及整个欧盟)的持续讨论。
加载和浏览数据
现在, 你已经收集了更多的背景信息, 是时候在这里下载数据集了。你应该获得” BelgiumTS for分类(裁剪的图像)”旁边列出的两个zip文件, 分别称为” BelgiumTSC_Training”和” BelgiumTSC_Testing”。
提示:如果你已经下载了文件, 或者将在完成本教程后下载了文件, 请查看下载数据的文件夹结构!你会看到测试以及培训数据文件夹包含61个子文件夹, 这是本教程中将用于分类的62种交通标志。此外, 你会发现文件的扩展名为.ppm或可移植Pixmap格式。你已经下载了交通标志的图像!
让我们开始将数据导入你的工作区。让我们从出现在用户定义函数(UDF)load_data()下面的代码行开始:
- 首先, 设置你的ROOT_PATH。该路径是你使用培训和测试数据创建目录的路径。
- 接下来, 你可以在join()函数的帮助下将特定路径添加到ROOT_PATH。你将这两个特定路径存储在train_data_directory和test_data_directory中。
- 你会看到, 之后可以调用load_data()函数, 并将train_data_directory传递给它。
- 现在, load_data()函数本身通过收集train_data_directory中存在的所有子目录开始。这样做是借助列表理解, 这是一种很自然的构建列表的方法-它基本上是说, 如果你在train_data_directory中找到了某些内容, 则将再次检查它是否是目录, 如果是, 你将其添加到列表中。请记住, 每个子目录都代表一个标签。
- 接下来, 你必须遍历子目录。首先初始化两个列表, 标签和图像。接下来, 收集子目录的路径以及这些子目录中存储的图像的文件名。之后, 你可以借助append()函数收集两个列表中的数据。
def load_data(data_directory):
directories = [d for d in os.listdir(data_directory)
if os.path.isdir(os.path.join(data_directory, d))]
labels = []
images = []
for d in directories:
label_directory = os.path.join(data_directory, d)
file_names = [os.path.join(label_directory, f)
for f in os.listdir(label_directory)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
ROOT_PATH = "/your/root/path"
train_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Training")
test_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Testing")
images, labels = load_data(train_data_directory)请注意, 在上面的代码块中, 训练和测试数据位于名为” Training”和” Testing”的文件夹中, 这两个文件夹都是另一个目录” TrafficSigns”的子目录。在本地计算机上, 这看起来像” / Users / Name / Downloads / TrafficSigns”, 然后有两个子文件夹, 分别是” Training”和” Testing”。
提示:通过srcmini的Python函数教程复习如何在Python中编写函数。
交通标志统计
载入数据后, 该进行一些数据检查了!你可以借助图像数组的ndim和size属性从一个非常简单的分析开始:
请注意, 图像和标签变量是列表, 因此你可能需要使用np.array()将变量转换为你自己的工作空间中的数组。这已经为你完成了!
请注意, 实际上, 你打印出的images [0]是一个由数组中的数组表示的单个图像!乍一看, 这似乎是违反直觉的, 但是随着你在机器学习或深度学习应用程序中进一步处理图像, 你会逐渐习惯这一点。
接下来, 你还可以略微看一下标签, 但是此时你应该不会看到太多惊喜:
这些数字已经使你对导入的成功程度和数据的确切大小有一些见解。乍一看, 一切都按照你期望的方式执行了, 如果你考虑到要处理数组中的数组, 则可以看到数组的大小相当大。
提示尝试向数组中添加以下属性, 以获取有关内存布局, 一个数组元素的长度(以字节为单位)以及该数组元素具有标志, itemize和nbytes属性所消耗的总字节数的更多信息。你可以在上面的srcmini Light块的IPython控制台中对此进行测试!
接下来, 你还可以查看交通标志的分布:
好工作!现在, 让我们仔细看看你制作的直方图!
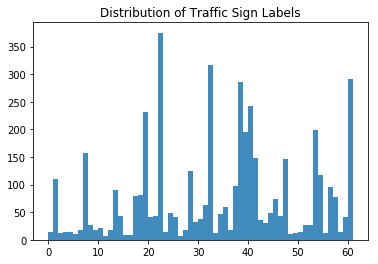
你清楚地看到, 并非所有类型的交通标志都在数据集中均等地表示。这是你稍后在开始对神经网络建模之前要处理的数据。
乍一看, 你会发现数据集中存在的标签比其他标签更多:标签22、32、38和61肯定会跳出来。现在, 记住这一点很高兴, 但是你一定会在下一部分中进一步介绍它!
可视化交通标志
先前的少量分析或检查已经使你对正在使用的数据有了一定的了解, 但是当数据主要由图像组成时, 应该通过可视化来探索数据。
我们来看看一些随机交通标志:
- 首先, 请确保在通用别名plt下导入matplotlib软件包的pyplot模块。
- 然后, 你将列出一个包含4个随机数的列表。这些将用于从上一节中刚刚检查的图像阵列中选择交通标志。在这种情况下, 你选择300、2250、3650和4000。
- 接下来, 你要说的是, 对于列表长度中的每个元素, 因此从0到4, 你将创建不带轴的子图(这样它们就不会全神贯注地运行, 你的关注点仅仅是在图片上!)。在这些子图中, 将显示图像数组中与索引i上的数字一致的特定图像。在第一个循环中, 你将传递300到images [], 在第二个循环中将传递2250, 依此类推。最后, 你需要调整子图, 使其之间具有足够的宽度。
- 剩下的最后一件事是借助show()函数显示你的绘图!
你去了:
# Import the `pyplot` module of `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images that you want to see
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images that you defined
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()正如你在此数据集中包含的62个标签所猜到的那样, 符号彼此不同。
但是你还注意到什么?再仔细看看下面的图片:

这四个图像的大小不同!
显然, 你可以使用traffic_signs列表中包含的数字进行修改, 并对此观察进行更彻底的跟踪, 但是, 尽管如此, 这是一个重要的观察, 当你开始进行更多的操作时, 需要考虑到这一点。你的数据, 以便你可以将其馈送到神经网络。
让我们通过打印形状, 包含在子图中的特定图像的最小值和最大值来确认不同大小的假设。
下面的代码与你用来创建上述绘图的代码非常相似, 但是不同的是, 在这里, 你将替换尺寸和图像, 而不是仅将图像彼此相邻地打印:
# Import `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images and add shape, min and max values
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()
print("shape: {0}, min: {1}, max: {2}".format(images[traffic_signs[i]].shape, images[traffic_signs[i]].min(), images[traffic_signs[i]].max()))请注意如何在字符串” shape:{0}, min:{1}, max:{2}”上使用format()方法来填写参数{0}, {1}和{2}定义。

现在你已经看到了松散的图像, 你可能还需要重新查看在数据探索的第一步中打印出的直方图。你可以通过绘制所有62个类的概述和一个属于每个类的图像来轻松实现此目的:
# Import the `pyplot` module as `plt`
import matplotlib.pyplot as plt
# Get the unique labels
unique_labels = set(labels)
# Initialize the figure
plt.figure(figsize=(15, 15))
# Set a counter
i = 1
# For each unique label, for label in unique_labels:
# You pick the first image for each label
image = images[labels.index(label)]
# Define 64 subplots
plt.subplot(8, 8, i)
# Don't include axes
plt.axis('off')
# Add a title to each subplot
plt.title("Label {0} ({1})".format(label, labels.count(label)))
# Add 1 to the counter
i += 1
# And you plot this first image
plt.imshow(image)
# Show the plot
plt.show()请注意, 即使你定义了64个子图, 但并非所有子图都将显示图像(因为只有62个标签!)。还要注意, 你不包含任何轴来确保读者的注意力不会偏离主要主题:交通标志!

正如你在上面的直方图中最容易猜到的那样, 带有标签22、32、38和61的交通信号明显更多。此假设现已得到证实:你看到有375个带有标签22、316和实例的标签。 32、285个带有标签38的实例, 最后282个带有标签61的实例。
你现在可能要问自己的最有趣的问题之一是, 所有这些实例之间是否存在联系-也许所有这些都是指示性标志?
让我们仔细看看:你看到标签22和32是禁止标志, 而标签38和61分别是指示性标志和优先标志。这意味着这四个之间没有直接联系, 除了数据集中大量存在的标志的一半是禁止类的事实。
特征提取
现在, 你已经彻底探索了数据, 是时候动手了!让我们简要回顾一下你发现的内容, 以确保你不会忘记操作中的任何步骤:
- 图片的大小不相等;
- 有62个标签或目标值(因为标签从0开始到61结束)。
- 交通标志值的分布是非常不平等的。数据集中大量出现的符号之间实际上没有任何联系。
现在, 你已经清楚了需要改进的地方, 可以从处理数据的方式入手, 以便可以将其馈送到神经网络, 也可以将其馈入任何模型。首先, 我们要提取一些功能-重新调整图像的比例, 然后将图像数组中保存的图像转换为灰度。之所以进行这种颜色转换, 主要是因为颜色在分类问题(例如你现在要回答的问题)中的重要性较小。但是, 对于检测而言, 颜色确实起了很大的作用!因此, 在这种情况下, 无需进行转换!
重新缩放图像
为了处理不同的图像尺寸, 你将要重新缩放图像;你可以借助skimage或Scikit-Image库轻松完成此操作, 该库是图像处理算法的集合。
在这种情况下, 转换模块会派上用场, 因为它为你提供了resize()函数。你会发现你再次使用列表理解功能将每张图片的尺寸调整为28 x 28像素。再一次, 你会看到真正形成列表的方式:对于在images数组中找到的每个图像, 你将执行从skimage库中借用的转换操作。最后, 将结果存储在images28变量中:
# Import the `transform` module from `skimage`
from skimage import transform
# Rescale the images in the `images` array
images28 = [transform.resize(image, (28, 28)) for image in images]这相当容易, 不是吗?
请注意, 图像现在是四维的:如果将images28转换为数组, 并且将属性形状连接到数组, 你将看到打印输出告诉你image28的尺寸为(4575、28、28、3)。图像为784维(因为你的图像为28 x 28像素)。
你可以通过重新使用上面使用的代码在traffic_signs变量的帮助下绘制4张随机图像来检查重新缩放操作的结果。只是不要忘记将所有对图像的引用更改为images28。
在这里查看结果:

请注意, 由于你已重新缩放比例, 因此最小值和最大值也已更改。它们现在似乎都在相同的范围内, 这确实很棒, 因为那样一来你就不必标准化数据了!
图像转换为灰度
如本节本节简介中所述, 当你尝试回答分类问题时, 图片中的颜色影响较小。这就是为什么你还会遇到将图像转换为灰度的麻烦。
但是请注意, 如果你不遵循此特定步骤, 也可以自行测试模型最终结果会怎样。
就像重新缩放一样, 你可以再次依靠Scikit-Image库来帮助你;在这种情况下, 你需要使用带有rgb2gray()函数的颜色模块才能到达需要的位置。
这将很容易!
但是, 不要忘记将images28变量转换回数组, 因为rgb2gray()函数确实希望将数组作为参数。
# Import `rgb2gray` from `skimage.color`
from skimage.color import rgb2gray
# Convert `images28` to an array
images28 = np.array(images28)
# Convert `images28` to grayscale
images28 = rgb2gray(images28)通过绘制一些图像仔细检查灰度转换的结果;在这里, 你可以再次使用并稍微修改一些代码以显示调整后的图像:
import matplotlib.pyplot as plt
traffic_signs = [300, 2250, 3650, 4000]
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images28[traffic_signs[i]], cmap="gray")
plt.subplots_adjust(wspace=0.5)
# Show the plot
plt.show()请注意, 你确实必须指定颜色图或cmap并将其设置为”灰色”才能以灰度图绘制图像。这是因为默认情况下, imshow()默认使用类似于热图的颜色图。在这里阅读更多。

提示:由于你已经在本教程中大量使用了此功能, 因此你可能会研究如何将其转化为功能:)
这两个步骤是非常基本的步骤。你可以尝试对数据进行的其他操作包括数据增强(旋转, 模糊, 移动, 改变亮度等)。如果需要, 还可以设置整个数据处理操作流水线, 通过该流水线发送图像。
使用TensorFlow进行深度学习
既然你已经探索和处理了数据, 现在是时候借助TensorFlow软件包构建神经网络架构了!
神经网络建模
就像你可能使用Keras一样, 是时候逐步构建神经网络了。
如果尚未这样做, 请在常规别名tf下将tensorflow导入工作区。然后, 你可以在Graph()的帮助下初始化Graph。你可以使用此函数定义计算。请注意, 对于Graph, 你无需进行任何计算, 因为它不包含任何值。它只是定义你要稍后运行的操作。
在这种情况下, 你可以使用as_default()来设置默认上下文, 该默认上下文将返回一个上下文管理器, 该管理器使此特定Graph成为默认图形。如果要在同一过程中创建多个图形, 请使用此方法:使用此功能, 你可以拥有一个全局默认图形, 如果你未明确创建新图形, 则将向其中添加所有操作。
接下来, 你准备将操作添加到图形中。你可能还记得与Keras一起工作时先建立模型, 然后在编译过程中定义损失函数, 优化器和度量。现在, 当你使用TensorFlow时, 这一切都会一步发生:
首先, 你要为输入和标签定义占位符, 因为你尚未输入”真实”数据。请记住, 占位符是未分配的值, 运行时将由会话初始化。因此, 当你最终运行会话时, 这些占位符将获取你在run()函数中传递的数据集的值!
然后, 你建立了网络。首先, 你需要借助flatten()函数来使输入变平, 这将为你提供形状为[None, 784]的数组, 而不是[None, 28, 28], 即灰度图像的形状。
拼合输入之后, 你将构建一个完全连接的层, 该层将生成大小为[None, 62]的logit。 Logits是对先前图层的未缩放输出进行操作的函数, 并且使用相对缩放来了解单位是线性的。
内置多层感知器后, 你可以定义损失函数。损失函数的选择取决于你手头的任务:在这种情况下, 你可以利用
sparse_softmax_cross_entropy_with_logits()这将计算logit和标签之间的稀疏softmax交叉熵。换句话说, 它测量类别互斥的离散分类任务中的概率误差。这意味着每个条目都是同一类。在此, 交通标志只能有一个标签。请记住, 虽然回归用于预测连续值, 但分类用于预测离散值或数据点类别。你可以用reduce_mean()包装此函数, 该函数将计算张量维度上元素的均值。
你还想定义一个培训优化器;使用的一些最流行的优化算法是随机梯度下降(SGD), ADAM和RMSprop。根据你选择的算法, 你需要调整某些参数, 例如学习率或动量。在这种情况下, 请选择ADAM优化器, 为其定义学习速率为0.001。
最后, 在进行培训之前, 你要初始化要执行的操作。
# Import `tensorflow`
import tensorflow as tf
# Initialize placeholders
x = tf.placeholder(dtype = tf.float32, shape = [None, 28, 28])
y = tf.placeholder(dtype = tf.int32, shape = [None])
# Flatten the input data
images_flat = tf.contrib.layers.flatten(x)
# Fully connected layer
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
# Define a loss function
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits = logits))
# Define an optimizer
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# Convert logits to label indexes
correct_pred = tf.argmax(logits, 1)
# Define an accuracy metric
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))你现在已经使用TensorFlow成功创建了你的第一个神经网络!
如果需要, 你还可以打印出(大多数)变量的值, 以快速回顾或检查一下刚刚编写的代码:
print("images_flat: ", images_flat)
print("logits: ", logits)
print("loss: ", loss)
print("predicted_labels: ", correct_pred)提示:如果看到类似”模块’pandas’没有属性’计算’”之类的错误, 请考虑通过在命令行中运行pip install –upgrade dask来升级dask软件包。有关更多信息, 请参见此StackOverflow帖子。
运行神经网络
现在你已经逐层建立了模型, 是时候实际运行它了!为此, 你首先需要在Session()的帮助下初始化一个会话, 你可以将上一节中定义的图形传递给该会话。接下来, 你可以使用run()运行会话, 以初始化变量的形式(在上一节中也定义过)将已初始化的操作传递给该会话。
接下来, 你可以使用此初始化的会话来开始时期或训练循环。在这种情况下, 选择201是因为你希望能够注册最后一个loss_value;在循环中, 使用训练优化器和你在上一节中定义的损失(或准确性)指标运行会话。你还传递了feed_dict参数, 通过该参数你可以将数据输入模型。每隔10个周期, 你将获得一条日志, 可让你更深入地了解模型的损失或成本。
正如你在TensorFlow基础知识部分中所看到的那样, 无需手动关闭会话。为你完成。但是, 如果你想尝试其他设置, 如果你已将会话定义为sess, 则可能需要使用sess.close()进行操作, 例如下面的代码块:
tf.set_random_seed(1234)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(201):
print('EPOCH', i)
_, accuracy_val = sess.run([train_op, accuracy], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)
print('DONE WITH EPOCH')请记住, 你也可以运行以下代码, 但是随后的代码将立即关闭该会话, 就像在本教程的简介中看到的那样:
tf.set_random_seed(1234)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(201):
_, loss_value = sess.run([train_op, loss], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)请注意, 由于不赞成使用initialize_all_variables()函数, 因此你要使用global_variables_initializer()。
你现在已经成功地训练了模型!那不是很难, 不是吗?
评估你的神经网络
你还不完全在那里;你仍然需要评估你的神经网络。在这种情况下, 你已经可以通过选择10张随机图像并将预测标签与真实标签进行比较, 从而一目了然地了解模型的性能。
你可以先将它们打印出来, 但是为什么不使用matplotlib自己绘制交通标志并进行视觉比较呢?
# Import `matplotlib`
import matplotlib.pyplot as plt
import random
# Pick 10 random images
sample_indexes = random.sample(range(len(images28)), 10)
sample_images = [images28[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "correct_pred" operation
predicted = sess.run([correct_pred], feed_dict={x: sample_images})[0]
# Print the real and predicted labels
print(sample_labels)
print(predicted)
# Display the predictions and the ground truth visually.
fig = plt.figure(figsize=(10, 10))
for i in range(len(sample_images)):
truth = sample_labels[i]
prediction = predicted[i]
plt.subplot(5, 2, 1+i)
plt.axis('off')
color='green' if truth == prediction else 'red'
plt.text(40, 10, "Truth: {0}\nPrediction: {1}".format(truth, prediction), fontsize=12, color=color)
plt.imshow(sample_images[i], cmap="gray")
plt.show()

但是, 仅查看随机图像并不能使你深入了解模型的实际效果。这就是为什么你要加载测试数据的原因。
请注意, 你使用了在本教程开始时定义的load_data()函数。
# Import `skimage`
from skimage import transform
# Load the test data
test_images, test_labels = load_data(test_data_directory)
# Transform the images to 28 by 28 pixels
test_images28 = [transform.resize(image, (28, 28)) for image in test_images]
# Convert to grayscale
from skimage.color import rgb2gray
test_images28 = rgb2gray(np.array(test_images28))
# Run predictions against the full test set.
predicted = sess.run([correct_pred], feed_dict={x: test_images28})[0]
# Calculate correct matches
match_count = sum([int(y == y_) for y, y_ in zip(test_labels, predicted)])
# Calculate the accuracy
accuracy = match_count / len(test_labels)
# Print the accuracy
print("Accuracy: {:.3f}".format(accuracy))请记住, 使用sess.close()关闭会话, 以防你未将tf.Session()与sess一起使用:启动TensorFlow会话。
接下来要去哪里?
如果要继续使用此数据集和本教程中放在一起的模型, 请尝试以下操作:
- 在将数据输入模型之前, 对数据应用正规化的LDA。这是来自收集和分析此数据集的研究人员撰写的原始论文之一的建议。
- 正如本教程本身所说, 你还可以查看可以对交通标志图像执行的其他一些数据增强操作。此外, 你还可以尝试进一步调整此网络;你现在创建的那个相当简单。
- 提前停止:在训练神经网络时跟踪训练和测试错误。当两个错误均下降时突然停止训练, 然后突然又上升-这表明神经网络已开始过度拟合训练数据。
- 尝试优化器。
确保检查一下Nishant Shukla编写的《使用TensorFlow进行机器学习》一书。
提示还请查看TensorFlow游乐场和TensorBoard。
如果你想继续使用图像, 一定要查看srcmini的scikit-learn教程, 该教程借助PCA, K-Means和支持向量机(SVM)来解决MNIST数据集。或看看其他使用比利时交通标志数据集的教程, 例如本教程。



