上一章软件工程教程请查看:软件设计基础
软件分析和设计包括所有的活动,这些活动有助于将需求规格转化为实现。需求规范指定了软件的所有功能性和非功能性期望。这些需求规范以人类可读和可理解的文档的形式出现,而计算机与这些文档无关。
软件分析和设计是中间阶段,它有助于将人类可读的需求转换为实际的代码。
让我们看看软件设计师使用的一些分析和设计工具:
数据流图
数据流图是信息系统中数据流的图形表示。它能够描述输入数据流、输出数据流和存储数据。DFD没有提到任何关于数据如何流经系统的内容。
DFD与流程图有明显的区别。流程图描述了程序模块中的控制流程。dfd描述了系统中各个层次的数据流。DFD不包含任何控件或分支元素。
DFD的类型
数据流图是逻辑的或物理的。
- 逻辑DFD——这种类型的DFD集中于系统过程和系统中的数据流。例如,在银行软件系统中,如何在不同实体之间移动数据。
- 物理DFD——这种类型的DFD显示了数据流是如何在系统中实际实现的。它更具体,更接近于实现。
DFD组件
DFD可以表示源、目标、存储和数据流使用以下组件-

- 实体——实体是信息数据的来源和目的地。实体由带有各自名称的矩形表示。
- 流程——对数据采取的活动和操作用圆形或圆边矩形表示。
- 数据存储—数据存储有两种变体—它可以表示为缺少两个较小边的矩形,也可以表示为只缺少一个边的开放矩形。
- 数据流——数据的移动用箭头表示。数据移动显示从箭头的底部作为它的来源到箭头的顶部作为目的地。
DFD级别
- 0级——最高的抽象级别DFD称为0级DFD,它将整个信息系统描述为一个隐藏所有底层细节的图。0级dfd也称为上下文级dfd。
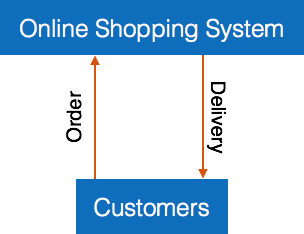
- 1级- 0级DFD被分解为更具体的1级DFD。第一级DFD描述了系统中的基本模块和各个模块之间的数据流。第一级DFD还提到了基本流程和信息来源。
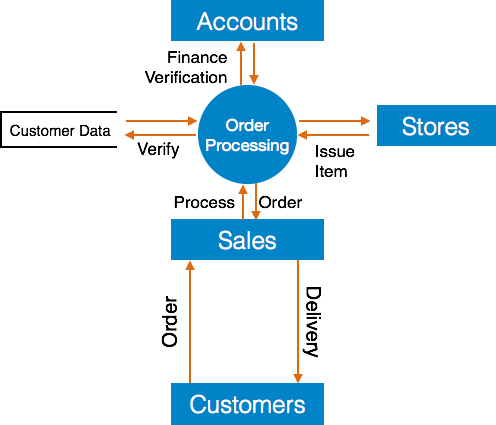
- 第2级—在这个级别上,DFD显示了第1级中提到的模块内部的数据流。
除非达到了所需的规范级别,否则可以将更高级别的dfd转换为更具体的、具有更深层次理解的更低级别的dfd。
结构图表
结构图是由数据流图衍生而来的图表。它比DFD更详细地描述了系统,它将整个系统分解为最低的功能模块,比DFD更详细地描述了系统各个模块的功能和子功能。
结构图表示模块的层次结构,每一层都执行特定的任务。
下面是结构图中使用的符号
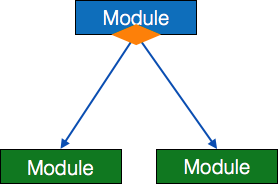
- 模块-它表示进程或子例程或任务。控制模块分支到多个子模块。库模块是可重用的,可以从任何模块调用。
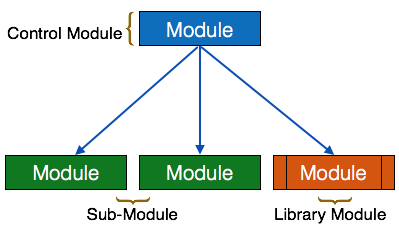
- 条件-它由模块底部的小钻石表示。描述了控制模块可以根据一定的条件选择任意子程序。
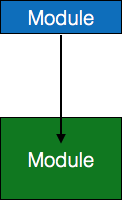
- 跳转——一个箭头指向模块内部,表示控件将跳转到子模块的中间。
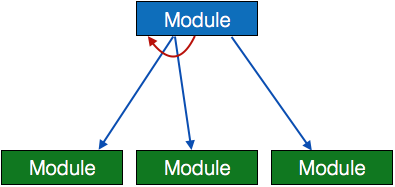
- Loop循环——一个弯曲的箭头表示模块中的Loop。模块的循环重复执行所覆盖的所有子模块。
- 数据流——一个有方向的箭头,箭头末端有一个空圆圈,表示数据流。
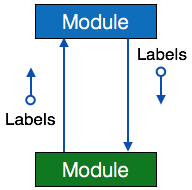
- 控制流——在控制流的末端有一个填充圆的方向箭头。
HIPO图
HIPO(分级输入过程输出)图是两种有组织的方法的结合,用来分析系统和提供文档的手段。HIPO模型是IBM在1970年开发的。
HIPO图表示软件系统中模块的层次结构。分析员使用HIPO图来获得系统功能的高级视图,它以分层的方式将函数分解为子函数,它描述了系统所执行的功能。
HIPO图很适合用于文档目的,它们的图形化表示使设计人员和管理人员更容易获得系统结构的图形化思想。
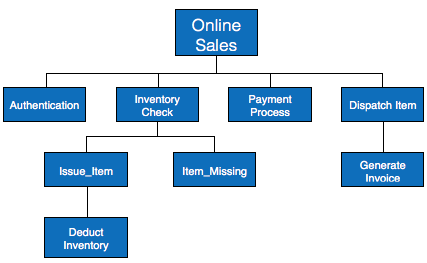
与描述模块中的控制流和数据流的IPO(输入过程输出)图不同,HIPO没有提供任何关于数据流或控制流的信息。
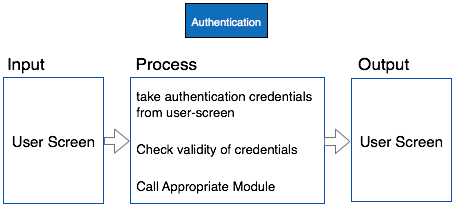
例子
软件程序的结构设计采用HIPO图、层次化表示和IPO图两部分,软件程序的文档也采用HIPO图、层次化表示和IPO图两部分。
结构化英语
大多数程序员不了解软件的全貌,所以他们只依赖于他们的经理告诉他们做什么。高级软件管理的责任是向程序员提供准确的信息,以开发准确而快速的代码。
使用图形或图表的其他形式的方法,有时可能会被不同的人以不同的方式解释。
因此,软件的分析师和设计师会提出结构化英语等工具。它只是对需要编写什么代码以及如何编写代码的描述,结构化英语帮助程序员编写无错误的代码。
使用图形或图表的其他形式的方法有时可能被不同的人解释为不同的,在这里,结构化英语和伪代码都试图减少这种理解上的差异。
结构化英语是在结构化编程范式中使用简单的英语单词。它不是最终的代码,而是一种描述,什么是需要编码和如何编码。以下是结构化编程的一些标记。
IF-THEN-ELSE,
DO-WHILE-UNTIL
Analyst使用存储在数据字典中的相同的变量和数据名,这使得编写和理解代码变得更加简单。
例子
我们以在线购物环境中的客户身份验证为例,本客户认证程序可以用结构化英语写成:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIF
用结构化英语编写的代码更像是日常口语,它不能作为软件代码直接实现,结构化英语独立于编程语言。
伪代码
伪代码更接近于编程语言。它可以被认为是一种增强的编程语言,充满了注释和描述。
伪代码避免了变量声明,但它们是使用一些实际编程语言的结构编写的,如C、Fortran、Pascal等。
伪代码比结构化英语包含更多的编程细节。它提供了执行任务的方法,就像计算机在执行代码一样。
例子
程序打印斐波纳契到n个数字。
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}
决策表
决策表以结构化的表格格式表示条件和为解决这些条件而采取的相应行动。
它是调试和防止错误的强大工具。它帮助将类似的信息分组到一个表中,然后通过组合表来提供简单和方便的决策。
建立决策表
要创建决策表,开发人员必须遵循四个基本步骤:
- 确定所有可能的处理条件
- 确定所有确定条件的操作
- 创建最大可能的规则
- 为每个规则定义操作
决策表应该由最终用户进行验证,最近可以通过消除重复的规则和操作来简化决策表。
例子
让我们举一个简单的互联网连接日常问题的例子。我们首先确定所有可能出现的问题,同时开始互联网和他们各自的可能的解决方案。
我们在列条件下列出了所有可能的问题,并在列操作下列出了预期的操作。
|
|
动作/条件 规则 | ||||||||
| 条件 | 显示连接 | N | N | N | N | Y | Y | Y | Y |
| Ping OK | N | N | Y | Y | N | N | Y | Y | |
| 打开网站 | Y | N | Y | N | Y | N | Y | N | |
| 动作 | 检查网线 | X | |||||||
| 检查网络路由器 | X | X | X | X | |||||
| 重新启动浏览器 | X | ||||||||
| 联系服务提供商 | X | X | X | X | X | X | |||
| 做任何行动 |
实体关系模型
实体-关系模型是一种基于现实世界实体及其相互关系概念的数据库模型。我们可以将真实的场景映射到ER数据库模型上。ER模型创建一组实体及其属性、一组约束和它们之间的关系。
ER模型最适合用于数据库的概念设计。ER模型可以表示为:
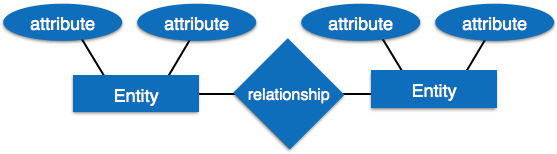
- 实体- ER模型中的实体是一个真实的世界,它具有一些属性,称为属性。每个属性由其对应的一组值(称为域)定义。
例如,考虑一个学校数据库。在这里,学生是一个实体。学生有不同的属性,如姓名,身份,年龄和阶级等。
- 关系——实体之间的逻辑关联称为关系。关系以各种方式映射到实体。映射基数定义两个实体之间的关联数量。
- 映射基数:
- 一个对一个
- 一个到多个
- 很多人一
- 多对多
数据字典
数据字典是关于数据的信息的集中收集。它存储数据的含义和来源、与其他数据的关系、使用的数据格式等。数据字典对所有名称都有严格的定义,以方便用户和软件设计者。
数据字典经常被引用为元数据(关于数据的数据)存储库。它是与软件程序的DFD(数据流图)模型一起创建的,并期望在DFD发生变化或更新时进行更新。
数据字典要求
在设计和实现软件时,通过数据字典引用数据。数据字典消除任何歧义的机会。它有助于保持程序员和设计人员的工作同步,同时在程序中各处使用相同的对象引用。
数据字典为一个地方的完整数据库系统提供了一种文档化的方法。使用数据字典对数据展开展开验证。
内容
数据字典应该包含以下信息
- 数据流
- 数据结构
- 数据元素
- 数据存储
- 数据处理
如前所述,数据流是通过dfd来描述的,并以代数形式表示。
| = | 组成 |
| {} | 重复 |
| () | 可选 |
| + | 和 |
| [ / ] | 或 |
例子
地址=门牌号+(街道/地区)+城市+州
课程编号=课程编号+课程名称+课程级别+课程成绩
数据元素
数据元素包括数据和控制项的名称和描述、内部或外部数据存储等,具体如下:
- 主名字
- 第二名(别名)
- 用例(如何以及在哪里使用)
- 内容描述(符号等)
- 补充资料(预设值、限制等)
数据存储
它存储数据从何处进入系统并存在于系统之外的信息。数据存储可能包括-
文件
- 内部软件。
- 外部软件,但在同一机器上。
- 外部软件和系统,位于不同的机器。
表
- 命名约定
- 索引属性
数据处理
数据处理有两种类型:
- 逻辑:正如用户看到的那样
- 物理:正如软件所看到的那样