一、编译器的逻辑结构
编译器的结构在逻辑上主要分为两部分:前端和后端,我们需要编译的源代码称为源语言,最终目标结构为机器语言或汇编语言,称为目标语言。前端处理主要是将源代码生成中间代码,中间代码还会经过优化,最后由后端处理生成最终的机器语言。
编译器前端又可以分为词法分析、语法分析、语义分析和中间代码生成,词法分析主要是对源代码文件中的字符进行切割(分词),分成一个个符号并生成符号标记树。语法分析是对符号标记树中的标记进一步分析语法,并生成语法树,语义分析是对源代码上下文的整体检查,最后根据生成的正确语法树翻译成中间代码。
编译器后端主要是生成机器语言,并进行相关的代码优化,编译器生成的机器语言根据硬件平台的不同而不同,比如X86,ARM,同样的C语言程序,在X86上的是X86汇编,而ARM平台则是ARM汇编。
编译器的结构图如下:
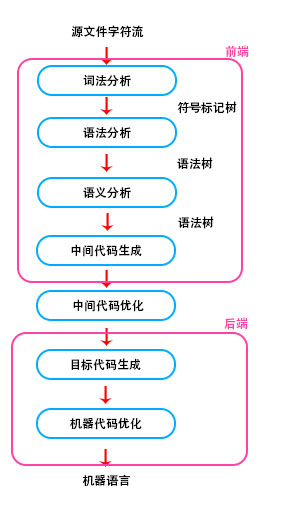
广泛来说,编译器的结构不一定是以上固定的结构,另外目前编程语言众多,其编译器也不尽相同,但其核心都会有词法分析和语法分析。这里也涉及到编译器和解析器的区别,一般来说,编译器是直接将源代码编译成可执行的程序,但是像java,javascript一些语言,其编译的结果并不能直接执行,需要依靠一个运行环境,比如java需要JVM,javascript则需要一个js引擎,如包装了V8引擎的Node.js。虽然运行方式不同,但是编译器和解析器的核心是相同的,所以我们学习的编译原理同样适用于解析器。
二、编译器的编译过程
对于编译原理我们始终要清楚,输入的源语言和输出的目标语言,编译器就是一个程序,它的实质是将源文件中的字符串翻译成机器语言的0和1,所以你看,编译器比起其它软件程序并没有多复杂,其重点在于翻译,理解编译器的实质可以让你不至于被新名词困惑住。
既然是翻译,那么我们很容易可以想到英语和汉语的翻译,比如:I am young.相信很多人都看到这句英语就立即知道汉语的意思了,怎么知道的?当然是根据单词的意思和语法了。编译器也是同样的道理,在生成机器语言之前,我们得确保源代码的语法没错对吧?我们在学习任何一种编程语言都需要学习语法,同样需要词法,词法的意思是该编程语言所使用的符号有哪些(就像英语中26个字母组成所有单词)。接着比较重要的就是上下文分析,就像上面的一句英语,如果还有其它句子组成一篇文章,则该句子需要结合上下文来理解。在编译器中,上下文分析指的是语义分析,类型检查,比如检查变量是否声明了,调用的函数是否存在,参数是否匹配等。
所以,编译器程序从源代码读取字符串,使用词法分析器对字符串进行切割,切割生成的字符标记生成一个字符标记树,接着进行语法分析和语义分析,处理结果都是树状的数据结构,树状的结构类似于下图,下图表示的是:
If(a==1)
b = 8;
else
c = 1;
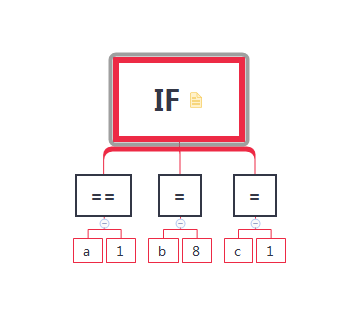
最终得到的正确结果就可以被生成机器语言了,那么显然需要涉及汇编语言,寄存器,以及代码优化。
到现在你可以看到,汇编原理其实就是研究语法分析、语义分析这些核心内容所使用的算法和数据结构。
三、编译实例
对于词法分析和语法分析,我们重点是学习它们的算法,至于实际运用中,其实我们可以利用工具生成相关的解析器,后面有时间我们会讨论如何实现自己的解析器。
我们来看一个,C++源代码的编译过程:
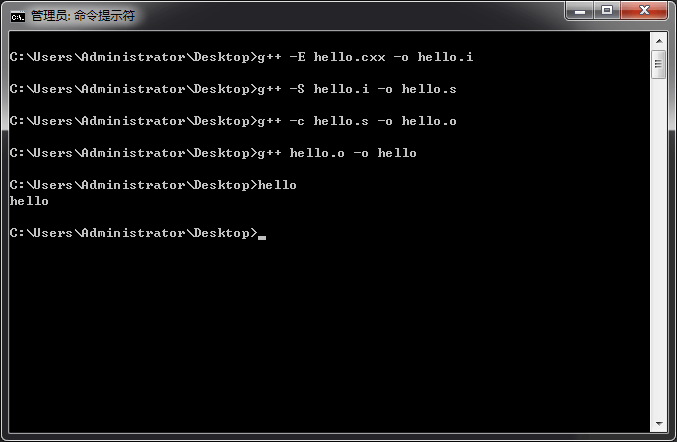
g++ -E表示预处理源文件,g++ -S开始编译,g++ -c生成字节码文件,我们可以使用objdump查看汇编代码:
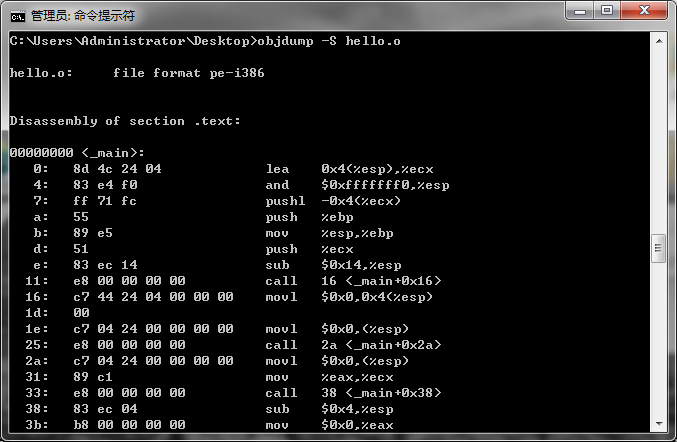
该文件是一个PE格式的文件,linux下的是ELF文件。上图就是编译器编译的目标文件内容,左边是十六进制机器码,右边是汇编。之前说过,汇编只是机器码的一种标记,看图你可以发现movl指令的机器码为c7,这是x86的汇编,换到ARM上可能又不同了。





