RANK
返回结果集的分区内每行的排名。 行的排名是相关行之前的排名数加一。
ROW_NUMBER 和 RANK 类似。 ROW_NUMBER 按顺序对所有行进行编号(例如: 1、2、3、4、5)。 RANK 为相应关联提供相同的数值(例如: 1、2、2、4、5)。
RANK是运行查询时计算出的临时值
语法
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )如果两个或多个行与一个排名关联,则每个关联行将得到相同的排名
DENSE_RANK
此函数返回结果集分区中每行的排名,排名值没有间断。 特定行的排名等于该特定行之前不同排名值的数量加一。
语法
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )如果两个或更多行在同一分区中具有相同的排名值,那么每个行将获得相同的排名
积分排名实现
数据准备
-- 创建积分表
Create table integral
(
userUid varchar(36),
integralScore decimal(18,2)
);
-- 创建用户表
Create table UserInfo
(
userUid varchar(36),
user_name varchar(100)
);使用 rank 函数查询积分排名
with integral AS
(
select userUid, ISNULL(SUM(integralScore), 0) as integralScore from integral group by userUid
)
,
ranks AS(
select rank() OVER(order by integralScore desc) as ranks,integral.integralScore,UserInfo.user_name from integral Inner Join UserInfo on integral.userUid=UserInfo.userUid
)
select * from ranks;
rank函数实现排名,排名不连续,排名会跳过序号。如上图所示。
使用 dense_rank 函数查询积分排名
针对上述情况可以使用dense_rank函数来解决,这样排名需要就会连续出现。
with integral AS
(
select userUid, ISNULL(SUM(integralScore), 0) as integralScore from integral group by userUid
)
,
ranks AS(
select dense_rank() OVER(order by integralScore desc) as ranks,integral.integralScore,UserInfo.user_name from integral Inner Join UserInfo on integral.userUid=UserInfo.userUid
)
select * from ranks;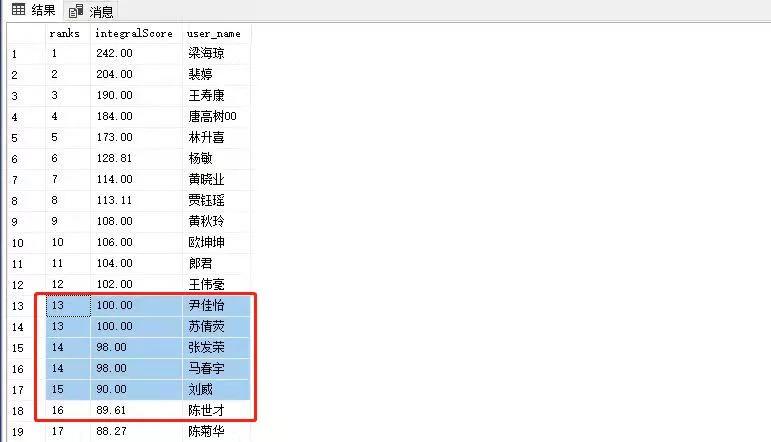
当使用dense_rank函数排名后,就完美避免了排名跳编号的问题。
(adsbygoogle = window.adsbygoogle || []).push({});
来源:https://www.02405.com/archives/9062



