前几天在微博上看到 @马克少年 的一条神微博:在评论区里分享了 1000 多张表情包。
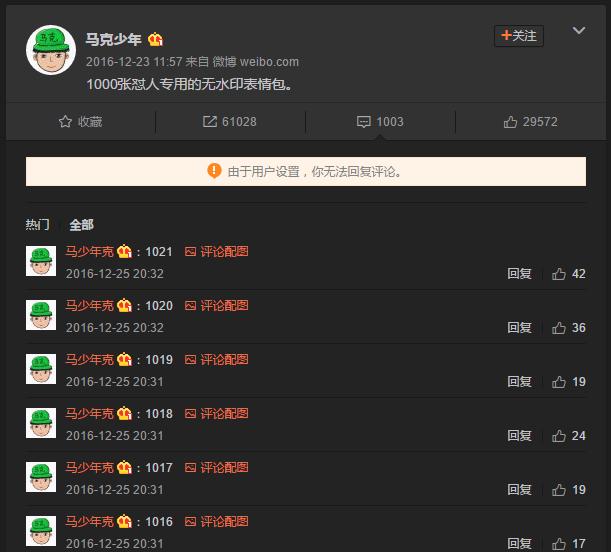
我这人一看到表情图就想保存下来。不过这么多表情图如果要手动的一张张点开并保存,真的是一件麻烦事,而且太蠢。
既然咱是玩技术的,就得用技术手段把它给全部保存下来。我看到微博的评论是采用 ajax 从后台加载出来的,于是第一步就想到了通过抓取它的接口评论数据。通过浏览器 F12 一监控,发现评论接口如下:
- http://weibo.com/aj/v6/comment/big?ajwvr=6&id=4055816330135380&root_comment_max_id=4056668591224614&page=4&filter=all&sum_comment_number=43&filter_tips_before=1&from=singleWeiBo&__rnd=1485224641725
通过猜测,评论接口中的 “page=4” 就是获取第四页的评论数据,那么我们可以通过修改它的值来获取其它页的评论。经过测试,发现果然没错。
不过在取回数据时发现,微博的评论接口里返回的数据内容并不完全是 json 格式,而是直接返回的 html,整个内容非常凌乱!
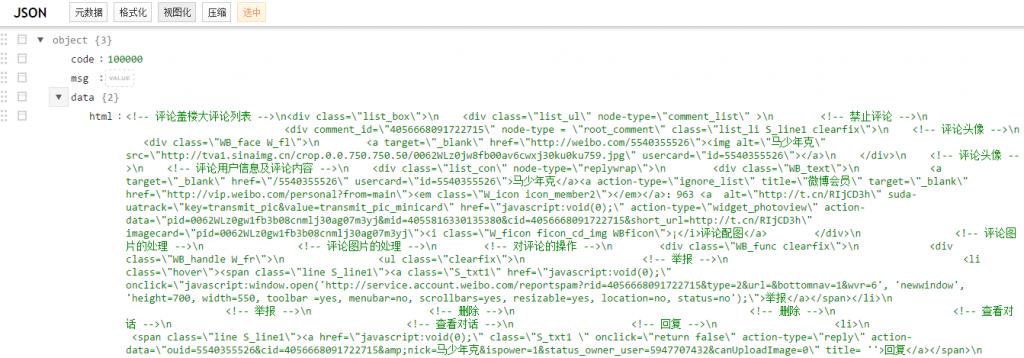
微博评论接口返回的数据
既然无论怎样都得到的是 html 内容,那还不如直接在尝试从前端来取得数据。
我的办法是先点击“查看更多”,把这条微博下的所有评论都加载出来:
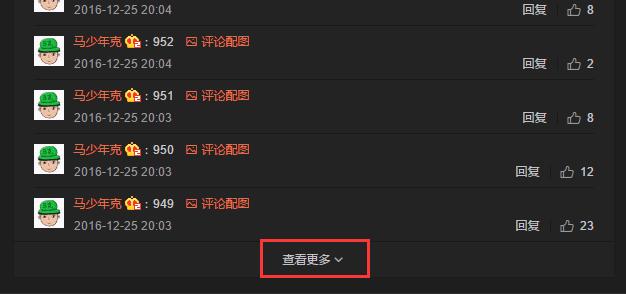
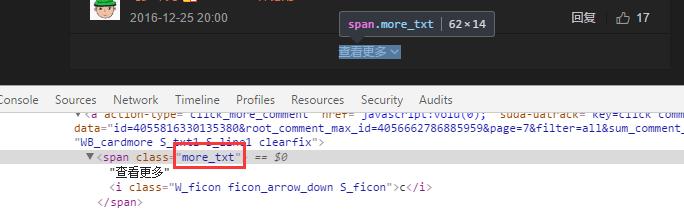
这里因为评论内容确实有点多,如果你要手动的一个个去点加载更多评论,也得点好一会儿。一个解决办法是可以写一个 js 脚本,利用 js 脚本自动点击 “more_txt” 这个 class。
待到评论完全加载出来了,再通过审查元素,保存 list_ul 这部分的所有 html 内容,这一步详见以下gif
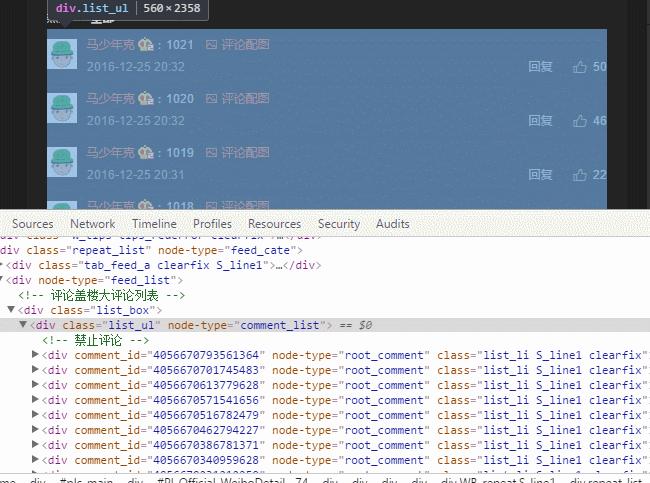
再新建一个文本文档,把刚刚获取到的 html 内容保存并另存为 html 格式。
再对获取到的评论部分 html 代码分析(别问我怎么分析的,只能是不断去试),发现评论部分的图片真实链接获取方式是 “http://ww2.sinaimg.cn/bmiddle/” 再加上 imagecard 中的 pid 值。比如说这条回复内容,其中真实的图片地址就是
http://ww2.sinaimg.cn/bmiddle/0062WLz0gw1fb3bbebmn1j316z0qomzz
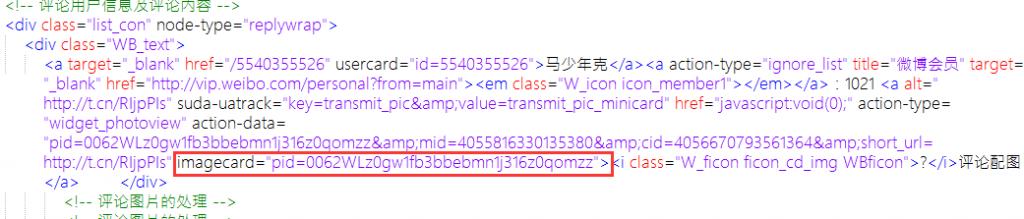
用正则表达式
- imagecard=”pid=([^”]*)”
提取出所有的 pid 值,然后补全前面的链接,再把获取的链接通过迅雷批量下载下来。至此,完美地保存下来了所有的图片!
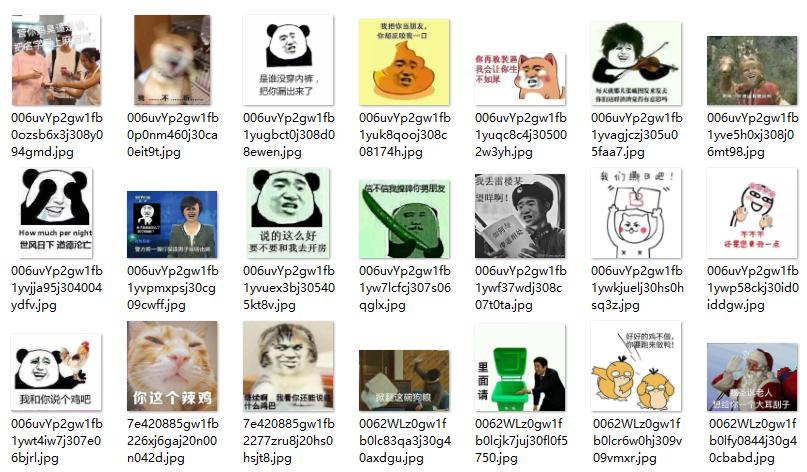
最后,我已将这些表情图打包,需要的可以前往下载:
来源:https://mkblog.cn/573/



