正常流程(如下图)是,引擎(engine)将url交给下载器(downloader),下载器来 进行数据下载,如果我们想导入selenium, 那么必须要阻断这个过程,并有selenium来代替,我们就需要通过修改downloadmiddleware中的process_request来实现。
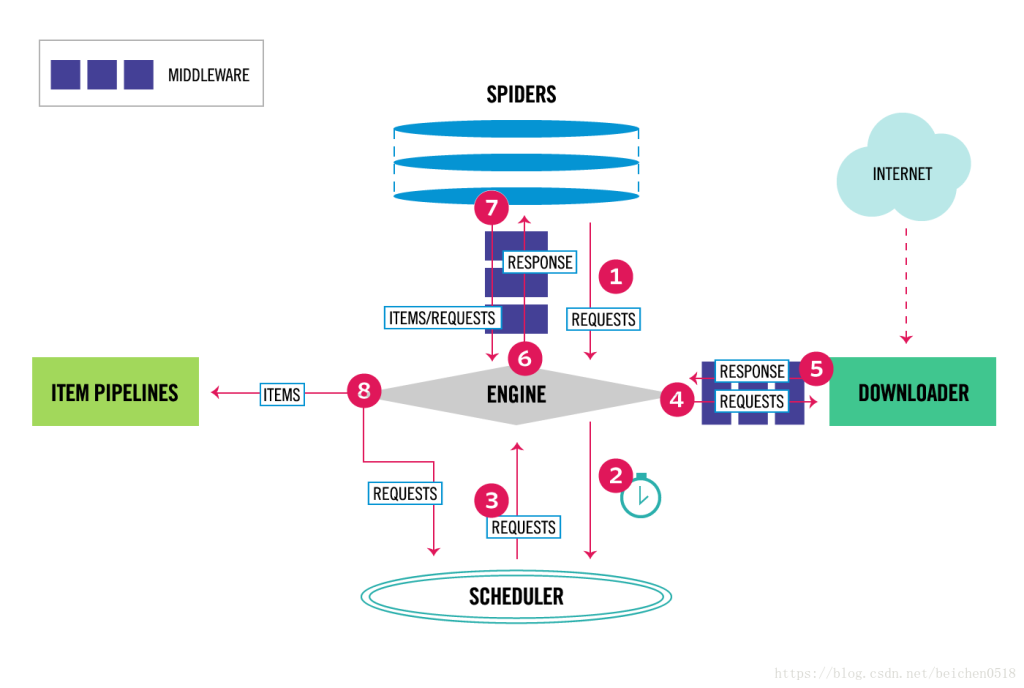
正常流程(如下图)是,引擎(engine)将url交给下载器(downloader),下载器来 进行数据下载,如果我们想导入selenium, 那么必须要阻断这个过程,并有selenium来代替,我们就需要通过修改downloadmiddleware中的process_request来实现。



